Windows on ARM





나는 Windows를 사랑한다. 정말로 사랑한다. 물론 Windows 3.1과 95에 대한 애착은 크지 않지만 NT커널 이후의 Windows는 정말 사랑한다. 또한 Windows 프로그래밍을 좋아한다. Visual Studio로 Windows프로그래밍을 하는 것은 즐겁다.
그래서 x86이외의 CPU에서 돌아가는 NT커널 기반의 Windows의 소식을 들었을때 무척 흥분했다. Visual Studio로 ARM디바이스에서 돌아가는 Windows 어플리케이션을 개발할 수 있다니!
물론 초기 Windows Phone 8과 Windows RT(Surface RT에서 돌아가는)에서 크게 실망했다. 당장 이 블로그만 검색해도 Windows Phone과 Surface RT에 대한 개발 스토리를 쉽게 찾을 수 있다(욕이 반 이상이다).
Windows 10 Moblie과 Windows 10으로 발전하면서 개발환경이 많이 좋아졌다. 그리고 내 불만도 줄긴 했지만 여전히 만족스럽진 않았다.
그 불만중 큰 부분이 Windows on ARM 디바이스를 위한 소프트웨어를 개발하기 위해선 반드시 UWP API를 사용해야 한다는 점이다. 현시점에선 UWP API는 분명히 많이 좋아졌지만 여전히 win32 API에 비해 기능이 제한적이다. win32로 개발했던 내 게임을 UWP로 포팅하는데 많은 시간을 소비했다. 대체 이런 짓을 왜 해야하는걸까? 라고 수도없이 생각했다.
그리고 몇 년전 MS는 ARM 디바이스에서 완전한 Window 10 OS가 돌아가는 Windows 10 on ARM 을 개발하고 있음을 발표했다. 이후로 삼성과 ASUS, HP 등 몇몇 회사에서 시험적인 Windows 10 on ARM 제품을 출시했다. Surface RT때부터 크게 아픔을 겪었던 나로선 매우 비관적인 시각을 가질수밖에 없었다. ARM에서 돌아가는 Windows 10을 개발하기 위해서 얼마나 많은 엔지니어들이 고생을 했는지는 안봐도 잘 안다. 그 분들을 존경한다. 하지만 현실적으로 보면 매우 비관적이다.
x86에뮬레이션은 불안정하고 느리다. ARM용 네이티브앱은 없다.
하지만 나는 소프트웨어 엔지니어로서 Windows 10 on ARM에 관심이 많다. Surface RT에서 크게 한방 얻어맞았고 Windows Phone에서 또 한방 맞았지만 그래도 관심이 많다. 최초 발표로부터 최근까지도 Windows 10 on ARM에 대해서 계속 관심을 가지고 있었다.
MS는 최근의 Surface이벤트에서 Surface Pro X를 발표했다. HP나 삼성의 제품이 이미 시장에 나와있으므로 제품 그 자체로는 크게 놀랄만한 사건은 아니었다. 다만 명백하게 손실을 안을게 뻔한 제품(나뿐만 아니라 리뷰어들 대부분이 생각하는것 같다)을 MS가 무려 Surface브랜드를 달고 출시했다는데 크게 놀랐다.
Surface 이벤트를 보면서 일반 소비자가 이 제품을 구입했을때는 크게 후회할거라고 확신했다. 지금도 그렇게 생각한다. 나 역시 소비자 입장으로는 Surface Pro 7을 구입해서 내 방 침대 머리맡에 있는 Surface Pro 2를 대체하고 싶었다. 정말 그럴 생각이었다.
그래도 궁금하긴 했다. 하드웨어의 명가 MS에서 Surface 이름을 달고 출시한 ARM디바이스, Surface Pro X의 성능은 어느 정도인가. x86에뮬레이션 성능 말고 ARM 네이티브 코드의 성능이 궁금했다. 확실히 몇 년 사이에 ARM계열 프로세서들의 성능은 놀랍게 향상됐다. MS는 Surface Pro X에 장착된 SQ1 프로세서(Surface Qualcomm이라고 한다)의 성능에 대해 대단한 자신감을 보였다(물론 난 믿지 않는다. 그렇게 자랑하던 Surface Book 1의 dGPU도 성능이 형편 없었거든.).
Surface Pro X의 실제 출시가 이루어진 후부터 유튜브와 리뷰 사이트에 올라온 Surface Pro X의 리뷰들을 열심히 살펴봤다. 그리고 크게 실망했다. 정작 내가 원했던 정보는 전혀 없었다.
비난하는 리뷰는 ‘느리고 배터리 소모가 빠르며 돌아가는 앱이 없다’는 얘기 뿐이다. x86에뮬레이션은 당연히 느리다. 당연히 배터리를 많이 소비한다.
극찬하는 리뷰는 ‘얇고, 이쁘고 가볍다’는 얘기 뿐이다. 바보냐? 디바이스는 악세서리가 아니라고. 비난하는 리뷰보다 이런 멍청한 리뷰에 더 화가 난다.
하여간 프로그래머 입장에서 궁금한건 ‘SQ1프로세서의 진짜 성능’, ‘Windows 10 on ARM의 안정성’, ‘네이티브 앱을 개발하기 위한 환경’이다.
몇 일간 리뷰들을 뒤져보다 결국 포기했다. 이런 멍청한 리뷰들에선 내가 원하는 정보는 얻을 수 없다.
그래서 그냥 내 돈 주고 Surface Pro X를 샀다.
협찬 따윈 없다! 내 돈주고 샀다!
테스트에 필요한 코드도 내가 직접 짠다!
이제 내가 궁금해하던 것들을 알 수 있다. 필요한 테스트는 내가 직접 진행한다.


테스트 목표 & 방향
나는 게임에 들어가는 소프트웨어를 만드는 프로그래머이므로…이 물건에서 게임을 잘 돌릴 수 있는지 여부가 제일 중요했다. 그렇지만 win32베이스에 ARM64 네이티브 앱으로 출시된 게임은 한 개도 없다. 있다해도 내가 맘대로 뜯어고칠수 없으니 어차피 의미는 없다.
그래서 내가 개발했던 게임과 개발중인 게임을 ARM64로 포팅하기로 했다.
2주 정도 테스트와 포팅을 병행했다.
ARM64를 지원하기 위해 x86/x64용 어셈블리어로 작성했던 코드들은 표준 C코드로 다시 짰다. 성능에 민감한 수학함수들의 경우 x86/x64에선 SSE/AVX를 사용하고 있다. 공정한 비교를 위해 이 함수들은 Neon(ARM64용 SIMD명령셋)용 코드를 추가로 작성했다.
테스트도 중요하지만 Surface Pro X를 손에 넣었기 때문에 당연히 내 게임은 Surface Pro X에서 ‘잘’ 돌아가야 한다. 내 소프트웨어 제품들의 타겟 디바이스가 하나 더 늘은 것이다. 내 게임은 Windows 10 on ARM에서 잘 돌아야 한다. 단순히 테스트만 한다면 좀더 빠르게 진행할 수 있었겠지만 게임이 잘 돌도록 코드를 계속 수정했기 때문에 예상보다 시간이 많이 걸렸다.
최종적으로 게임이 잘 돌아가게 됐다고 판단한 후에 실질적인 테스트를 진행했다.
산술 연산 테스트의 경우 게임에서 사용중인 코드를 그대로 사용했다.
내 게임과 툴에서 사용하는 기능이 얼마나 잘 돌아가는지를 테스트 했다.
그리고 미리 말해두지만 ARM vs x86의 성능 비교가 아니다. 테스트에 사용한 ARM 프로세서는 SQ1프로세서서 하나 뿐이다. x86 CPU는 모두 intel 제품이다.
그러니 정확히는
‘Qualcomm에서 만든 Microsft SQ1프로세서의 ARM64네이티브 성능 vs intel x86 프로세서의 성능 비교’
이다.
x86에뮬레이션에서의 성능도 측정했다. 3 – 8 배 정도는 느리니까 그냥 참고만 하기 바란다. 이 테스트의 목적은 SQ1프로세서에서의 ARM64 네이티브 성능을 알기 위함이다.
참고로 SQ1 프로세서에서 SSE 명령어셋도 에뮬레이션 가능하다. SSE4까지 에뮬레이션 가능하다. AVX는 불가능하다.
산술연산 테스트
싱글스레드로 테스트한다. 소요시간을 측정하지 않는다. 소모한 클럭을 측정한다. 클럭 주파수는 당연히 x86 cpu가 높기 때문에 소요시간을 측정하면 x86이 무조건 빠르게 나온다. 따라서 각각의 오퍼레이션이 얼만큼의 클럭을 소모하는지를 측정한다.
– big.LITTLE Architecture on SQ1 Processor
여기서 짚고 넘어가야하는 것이 있다. SQ1프로세서는 다른 ARM AP들과 마찬가지로 big.little아키텍처를 사용한다. 고성능의 4개의 Big Core와 저성능의 4개의 little Core로 구성돼 있다. big core는 Gold Core라 부르고 little core는 Silver Core라 부른다. 클럭만 다른게 아니고 명령어 효율 자체가 다르다.
little core가 0,1,2,3번, big core가 4,5,6,7번이다.8개 동시에 사용될 수 있다. 이 순서를 반대로 생각했기 때문에 처음에 잘못된 결과를 얻었다. 이후 아예 Gold core와 Silver Core를 명시적으로 지정해서 측정했다.
– SIMD(Single Instruction Multiple Data)
명시적으로 SIMD코드를 작성하지 않고 표준적인 C코드를 작성할 경우 컴파일러는 자동으로 SIMD처리를 해주지 못한다. 단 SIMD 명령어셋의 싱글 명령들과 SIMD용 레지스터는 사용한다. 기존의 FPU를 사용하는것보다 빠르다.
이 테스트에서 SIMD로 표기한 경우 명시적으로 SIMD코드를 작성한 경우이다.
No SIMD로 표시한 경우 표준적인 C코드로 작성했음을 의미한다. 그러나 컴파일러는 FPU대신 SIMD레지스터와 명령어를 사용하므로 그래도 FPU를 사용하는것보다 빠르다. 따라서 SIMD코드와 성능 차이가 거의 없거나 때때로 더 빠를 수 있다.
x86/x64용 SIMD코드는 SSE를, ARM64용 코드는 Neon을 사용했다.
x86은 AVX를 사용하면 성능을 더 올릴 수 있는 가능성이 있다. 한편 나는 Neon코드를 이번에 처음 작성해봤다. 내 코드는 충분히 효율적이지 못할수 있다. 따라서 최대 성능이 어느쪽이 높은지를 정확히 판단할 수 없다.
이 테스트는 현대 ARM64프로세서의 성능이 어느 수준까지 왔는지를 알기 위함이지 순위경쟁을 하려는게 아니다.
4칙연산 테스트
4칙연산 테스트다. 메모리 절약을 위해서 게임에선 3차원 벡터(float3)를 주로 사용한다. float3타입은 메모리에서 한번에 읽어들일수 없고 한번에 써넣을수 없다. 따라서 메모리에 읽고쓰는 동작에서 추가적인 비용이 발생한다. 이 테스트는 단순한 산술연산을 얼마나 빠르게 하는지 테스트가 목적이기 때문에 4차원(float4)벡터를 사용했다.
덧셈과 뺄셈은 기본적으로 같은 연산이므로 뺄셈은 따로 테스트하지 않았다.

Add or Sub Or Mul or Div 테스트는 같은 오퍼레이션을 반복하는 대신, 전달된 벡터배열의 인덱스에 따라 4가지 연산으로 분기한다. 분기하는 상황에서 캐시미스를 유도하고 분기예측에 혼란을 주기 위함이다. 이 테스트에서는 intel x86 CPU가 확실히 우월함을 보이고 있다.
Vector 및 Matrix 연산 테스트
게임 프로그래밍에서 많이 사용하는 함수들이다. 내 게임에서 실제로 사용하는 함수들을 사용했다.
TransformVector_xxxx()함수들은 float3 스트림을 배열형태로 전달하기 때문에 함수호출 비용은 무시해도 좋다. 그러나 Matrix곱셈이나 Normalize()함수, CrossProduct(), DotProduct()등은 함수 한번에 한번의 오퍼레이션을 수행하므로 소모된 클럭에는 함수 호출 비용이 포함되어있다.
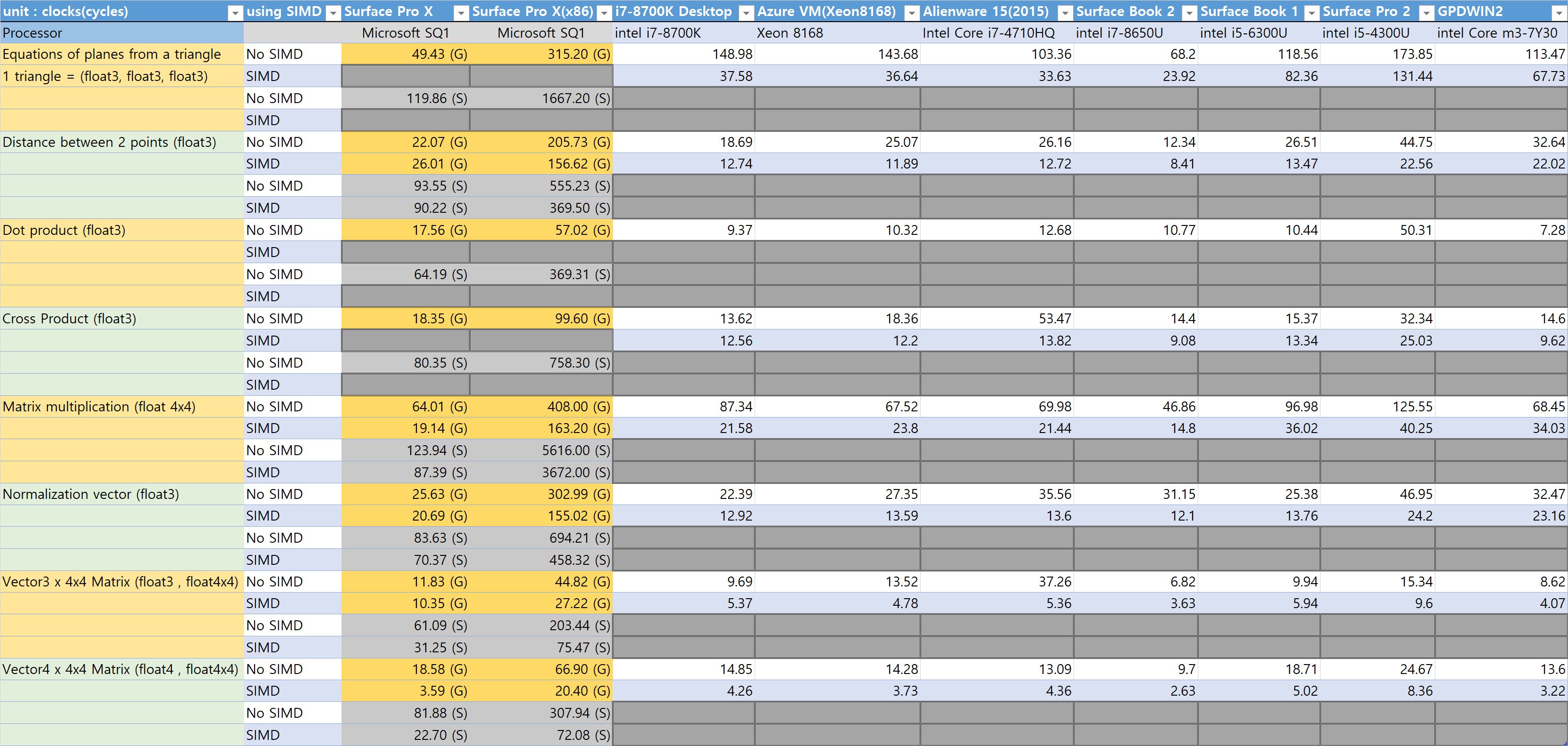
산술연산 테스트 결론
결과만 놓고 보면 intel x86이 빠르다. 하지만 당초 예상과는 달리 크게 성능이 뒤지지는 않는다. 또한 일부 ARM64가 더 빠른 경우도 있다. SIMD성능으로 보면 차이가 더 작다.
전체적으로 x86계열이 더 좋은 성능을 보인다. 하지만 이 정도의 성능 차이는 게임에서 크게 체감할 정도는 아니라고 생각한다.
즉 게임 돌리기엔 충분한 성능이다.
memcpy 테스트
VC++의 memcpy()를 사용해서 1GiB의 메모리를 복사한다. 여기서는 멀티 스레드를 사용한다.
1GiB의 메모리를 활성화된 스레드 개수로 나눠서 동시에 모든 스레드가 카피를 진행한다.
스레드간 동기화는 필요하지 않으므로 lock은 사용하지 않는다.

memcpy 테스트 결론
측정된 bandwidth는 SQ1프로세서의 공식적인 bandwidth와 intel CPU들의 공식적인 bandwidth 수치에는 도달하지 못한다.
하지만 memcpy()는 아주 많이 사용되는 메모리 카피 함수이고 대부분의 경우 높은 성능을 보장하기 때문에 memcpy()비교는 충분히 의미가 있다.
SQ1프로세서의 메모리 전송 능력은 매우 훌륭하다. 4채널 버스를 사용하는(명백하게 공식 스펙으로 대역폭이 높은) xeon cpu를 제외하고 2채널 버스를 사용하는 다른 x86 cpu들보다 성능이 높다.
Multithreading 응답성 테스트
context switching 비용, 스레드간 동기화에 필요한 lock의 비용이 얼마나 높은지를 측정하는 테스트이다.
처음 내 게임과 툴 코드들을 ARM64로 포팅했을때 성능이 만족스럽지 못했다. 멀티스레드로 돌아가는 툴들에서 특히 성능이 나빴으므로 ‘ARM64에서 멀티스레드 응답성에 문제가 있지 않을까’ 라고 추측했다.그래서 이 테스트를 진행했다.
기본적으로 이 테스트는 4바이트 변수가 특정 값에 도달할때까지 여러개의 스레드가 경쟁적으로 값을 증가시킨다. 다만 각 테스트 별로 동기화를 위한 방법이 다르다.
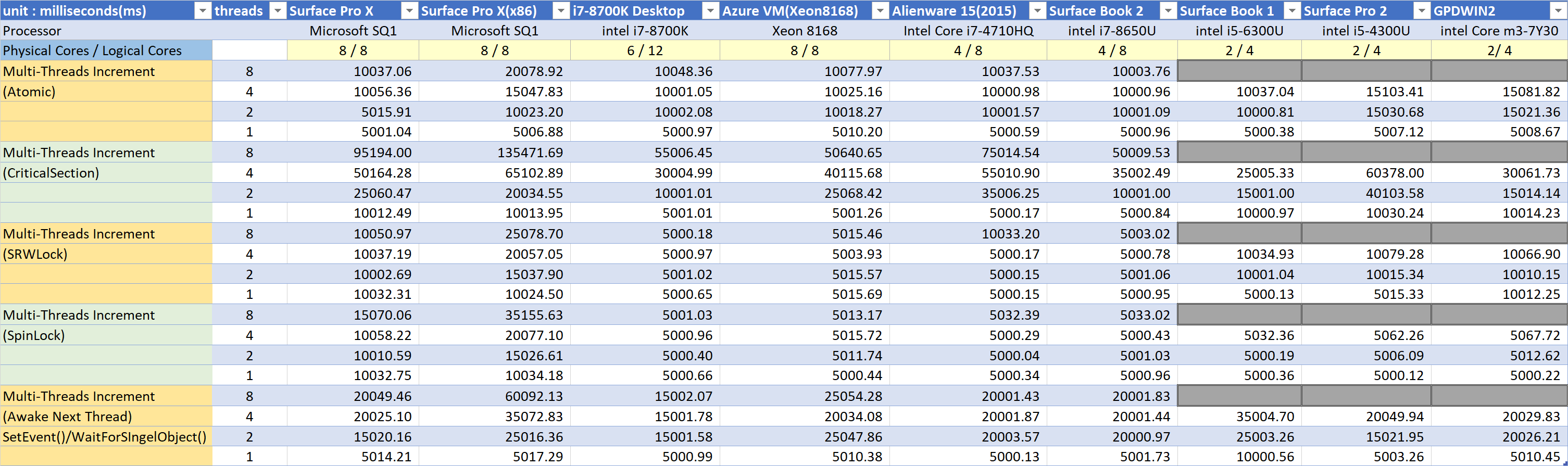
atomic increment테스트는 lock객체를 사용하지 않고 4바이트 변수값을 증가시키는 테스트다. x86이라면 어셈블리어로 lock inc dword ptr[mem] 한 줄로 표현된다. ARM CPU에 패널티가 있는지가 궁금했다. 1,4,8 스레드에서 SQ1프로세서와 intel x86은 거의 동일한 성능을 보여준다. 2스레드에선 SQ1프로세서의 성능이 더 뛰어난것으로 측정된다.
Critical Section 테스트는 critical section으로 락을 걸고 변수값을 증가시킨다. critical section으로 감싼 코드 블럭에 다른 스레드가 먼저 진입한 경우 늦게 진입하는 스레드는 먼저 진입한 스레드가 critical seiction에서 나갈때까지 스케쥴링 되지 않는다. 즉 wait상태가 된다. 다시 스케쥴링 될때는 지연시간이 걸린다. 스레드 개수가 많아지면 더욱 성능이 저하된다. 매우 나쁜 상황이다. 이 상황에서 각각의 CPU들이 얼마나 성능이 저하되는지를 알고 싶었다.
이런 상황에서 SQ1프로세서의 성능이 크게 저하되는것으로 보인다. 만약 critical section이나 비슷한 방식의 동기화를 많이 쓰는 어플리케이션이라면 성능 저하의 소지가 있다고 본다.
SRWLock은 최근 많이 쓰이는 경량 lock이다. 내부적으로 spin lock으로 구현되어있다. 매우 효율적인 코드로 작성되어있다. spin lock만 사용하면 먼저 진입한 스레드가 장시간 빠져나오지 않을 경우 진입을 기다리는 스레드가 바쁘게 작동하기 때문에 전체적으로 시스템 성능을 떨어뜨릴 수 있다. SRWLock은 이에 대한 대비가 되어있다. 진입을 대기하는 스레드는 일정 회수 이상 진입에 실패하면 Wait상태가 되므로 성능저하를 피할 수 있다.
x86 cpu에서 월등하게 응답성이 좋다.
spin lock테스트는 내가 직접 만들어서 사용하는 spin lock을 이용해서 동기화한다. SRWLock과 비슷하지만 먼저 진입한 스레드가 장시간 빠져나오지 않을 경우에도 대기중인 스레드가 wait하지 않는다. 명백하게 몇백 클럭 이내로 끝날 정도의 코드블럭을 동기화하는데 사용한다. lock cmpxchg명령을 사용하며 spin lock구현 자체는 SRWLock과 거의 같다.
이 테스트에서도 x86이 월등히 성능이 좋다.
spin lock사용시 SQ1 ARM64의 성능저하
spin lock(SRWLock을 포함하여) 사용시 SQ1의 성능이 x86보다 많이 떨어진다.
측정 단위가 ms이기 때문에 x86쪽이 클럭이 높아서 더 빠르게 측정되는것처럼 보일수 있다. 하지만 모든 x86 CPU가 Surface Pro X보다 빠르게 측정된다. 기본 1GHz로 작동하는 GPDWIN2조차도 Surface Pro X보다 빠르다. spin lock획득에서 SQ1프로세서가 spin lock을 획득할때 상당한 시간을 소모하고 있음을 알 수 있다.
이유가 궁금해서 어셈블리어 코드를 확인했다. 명백한 원인은 찾지 못했다.
처음엔 ARM에서의 CAS구현이 loop를 돌면서 시도하는 방식이고 그에 따라 코드도 길어지기 때문에 더 느린거라고 생각했다. x86의 경우 lock cmpxchg 명령어 한줄로 끝나지만 내부적으론 루프를 돌 것이다. 그럼에도 불구하고 x86의 방식이 더 효율적일것이다. 그렇게 생각했다.
[_InterlockedCompareExchange() – x64]

[_InterlockedCompareExchange() – ARM64]

그런데 atomic increment테스트에서 x86과 ARM의 성능의 차이는 거의 없었다. 오히려 2스레드에선 ARM64가 더 빨랐다.
여기서 사용하는 _InterlockedIncrement() 어셈블리 코드를 확인해 보면 다음과 같다.
[_InterlockedIncrement() – x64]

[_InterlockedIncrement() – ARM64]

ARM64의 경우 베타적 쓰기 작업을 수행하는 코드는 _InterlockedCompareExchange()와 똑같다. 코드도 x86에 비해 훨씬 길다. 그런데도 성능이 똑같거나 더 높게 측정된다.
단순히 arm64쪽이 코드가 길어서 느린거라면 atomc increment에서도 arm64쪽이 많이 느렸어야 한다.
난 CPU전문가가 아니고 ARM에 대해선 더더욱 알지 못한다. 결국 이유를 알 수 없다고 결론지었다.
확실한건 spin lock을 사용하는 경우 intel x86이 훨씬 빠르다는 것이다.
(Awake Next Thread)테스트는 wait 상태의 스레드가 깨어날때 얼마나 지연시간이 있는지를 테스트한다.
예를 들어 3개 스레드로 테스트하는 경우,
각각의 스레드들이 서로 꼬리를 물고 작동된다. 이것은 일종의 라운드 로빈이다.
- 0번 스레드는 변수값을 증가시킨 뒤 SetEvent(event[1])을 호출해서 1번 스레드를 깨운다.그리고 WaitForSingleObject(event[0]);를 호출해서 대기상태에 들어간다.
- 1번 스레드는 변수값을 증가시킨 뒤 SetEvent(event[2])를 호출해서 2번 스레드를 깨운다.그리고 WaitForSingleObject(event[1]);를 호출해서 대기상태에 들어간다.
- 2번 스레드는 변수값을 증가시킨 뒤 SetEvent(event[0])를 호출해서 0번 스레드를 깨운다.그리고 WaitForSingleObject(event[2]);를 호출해서 대기상태에 들어간다.
- 변수값이 목표값에 도달할때까지 이를 반복한다.
결과를 보면 SQ1 프로세서와 intel x86프로세서 사이에 의미 있는 성능 차이는 없어보인다.
다수의 스레드가 경쟁상태가 아니라면 멀티 스레드 응답성은 intel x86과 SQ1프로세서간에 차이가 없다고 볼 수 있다.
Multithreading 응답성 테스트 결론
다수의 스레드가 경쟁적으로 lock을 획득하려고 하는 경우(spin lock을 포함하여)에 SQ1프로세서가 intel x86보다 성능이 떨어지는 것으로 보인다.
동기화가 필요없을 경우 스레드가 스케쥴링되는데 있어 지연시간은 차이가 없어보인다.
다수의 코어를 총동원하는 작업에서 스레드 간의 동기화가 필요하다면 x86에서 더 좋은 성능을 얻을 수 있을것이다.
voxel data처리 테스트
내가 개발중인 voxel 기반의 게임 프로젝트가 있다.
여기서 늘 사용하는 툴과 게임 기능을 테스트 한다.
멀티스레드로 CPU성능을 최대한 사용하는 테스트이고 GPU성능도 중요하다.
3가지 테스트를 진행한다.
Loading map of voxels
50cm x 50cm x 50cm 짜리 복셀 1500만개로 이루어진 맵을 한번에 로드한다. 실제 게임에선 현재 위치 기준으로 일부 데이터만을 서버로부터 전송받는다. 오프라인 모드에서 한번에 로드할 수 있다.
복셀 데이터는 압축되어 있다. 파일 로딩 후 압축을 풀어서 vertex,index데이터를 만들고 충돌처리용 삼각형 데이터를 생성한다. 이 작업들은 core개수만큼의 다수의 스레드가 동시에 진행한다. 기하 데이터를 생성하고나면 라이트맵을 계산한다. 라이트맵 계산을 아직 완료하지 못한 경우 흰색으로 렌더링된다. nvidia GPU를 장착한 경우 라이트맵 게산에 CUDA를 사용할 수 있다. CUDA를 사용하면 압도적으로 성능이 좋다.
Baking Light-map
복셀월드 전체는 라이트맵을 사용한다. 월드를 로딩한 직후에, 또는 지형의 일부가 변형됐을때에 자동으로 라이트맵을 다시 계산한다. 그리고 수동으로 한번에 월드 전체의 라이트맵을 다시 계산할 수 있다. 논리 코어 개수만큼의 스레드가 라이트맵을 계산하고 업데이트한다.
라이트맵 계산이 끝나고 텍스처에 업데이트 될때까지 게임 프레임 갱신은 중단된다. 라이트맵 계산에 얼마만큼의 시간이 걸리는지를 측정한다. (여기서도 CUDA를 사용할 수 있다. 유감스럽게도 Surface Pro X에선 CUDA를 사용할 수 없다.)
Voxelization
게임에 필요한 지형 데이터를 이미 만들어진 삼각형 기반의 모델링 데이터로부터 얻기 위한 기능이다.
삼각형 베이스의 모델링 데이터를 복셀 데이터로 변환한다. 이런 류의 게임에서 필요한 복셀 데이터는 눈으로 보기에 복셀인것만으로는 충분하지 않다. 내부가 꽉찬 solid voxel data여야한다. 따라서 삼각형과 단순 교차 판정만으로는 원하는 복셀 데이터를 얻을 수 없다. 여러가지 방법이 있지만 꽤 무식하고 신뢰할만한 방식을 사용한다.
여기선 CPU와 GPU의 파워를 최대한 활용한다.
DirectX 11을 사용하면 부분적으로만 멀티 스레드 억세스가 가능하므로 DirectX 12를 사용한다. 개인적으로 DirectX 12의 성능에 대해선 매우 비관적이다. 할 말이 많지만, 이 경우에는 DirectX 12쪽이 성능이 조금 더 잘 나온다. 스레드 개수만큼의(논리 코어 개수만큼의) Commane Queue를 만들어서 GPU의 H/W queue를 남김없이 채운다.
영상을 보면 테스트 내내 CPU와 GPU점유율이 100%에 도달하고 있는걸 확인할 수 있다.
Surface Pro X vs intel x86 + dGPU devices

Loading map of voxels 테스트 결과
SurfaceBook 2의 절반 정도의 성능을 보여준다. 디바이스의 등급을 생각하면 나쁘지 않은 수치라고 생각한다. 처음엔 Surface Pro 2보다 성능이 더 떨어질걸로 예상했다. 예상을 뒤엎고 GPDWIN2, Surface Pro 2보단 월등한 성능을 보여준다. 처음 이 게임을 개발할때 최소 장비로 Surface Pro 2를 생각했으니 이 정도면 만족스럽다.
Baking Light-map 테스트 결과
놀랍게도 Surface Book 1보다 빠르다. 4개 코어가 다소 멍청한 놈들이지만 그래도 8코어의 위력을 보여준다. 무려 Surface Book 2의 70% 수준이다. 예상보단 훨씬 높은 성능이다.
Voxelization테스트 결과
결과를 보면 Surface Pro 2보단 빠르지만 GPDWIN2보다도 느리다. 예전에 개발했던 게임을 DX12로 돌렸을때 심각하게 성능 저하가 있었다. 퀄컴의 DX12용 GPU드라이버는 성능상의 문제가 있다고 추측한다.
voxel data처리 테스트 결론
4개 core가 little코어이기 때문에 아무래도 기대만큼의 멀티 스레드 성능은 보여주지 못한다.
CPU + GPU로 협업을 할 경우 특히 성능이 떨어진다. 드라이버의 성능에 문제가 있다고 생각한다. GPU H/W queue에 command를 전송하는 기능에 문제가 있어 보인다.
게임 fps 테스트
오래전에 개발했던 게임으로 프레임레이트를 측정했다.
오래전에 개발한 게임이지만 계속 코드를 고쳐왔기 때문에 코드는 최신이다. DirectX 12도 지원한다. 퀄컴의 DirectX용 GPU드라이버는 Draw call(DrawPritimitive() 등…) 호출이 많아지면 급격히 성능이 떨어진다. 커맨드를 전송하는데서 병목이 걸리고 이 동안 GPU가 펑펑 논다.
이 게임은 draw call이 많지 않다. 따라서 GPU점유율이 100%에 가까운 상황을 만들 수 있다.
GPU 점유율이 100%에 가까운 상태에서의 성능 비교를 할 수 있다.
비교적 오브젝트가 많은 마을맵을 로딩해서 같은 위치,같은 방향의 카메라 뷰를 설정한다. 해상도별로 프레임 레이트를 측정한다. 1920×1080을 공통으로 테스트한다. 참고삼아 디바이스별로 최대 해상도를 테스트했다.

중급 이상의 dGPU를 장착한 디바이스에 비하면 형편없는 프레임 레이트지만 내장 GPU치고는 상당한 성능을 보여준다. 거의 Surface Book 1의 dGPU에 필적하는 성능이다. 아마 대부분의 x86 Surface Pro제품들에 비해서도 비슷하거나 더 높은 성능을 보여줄거라고 생각한다. Surface Pro 7의 인텔 내장 GPU와 비교를 하고 싶지만 Surface Pro 7을 가지고 있지 않으므로 아쉽게도 테스트 하지 못했다.
게임 fps 테스트 결론
GPU의 하드웨어 성능은 충분하다. 아니 충분한것 이상으로 좋다. AAA게임을 돌리기엔 무리지만 인텔 내장 GPU로 돌아가는 게임이라면 무리없이 돌릴 수 있는 성능이다.
다만 퀄컴의 DirectX용 GPU드라이버에는 문제가 있다. 성능상의 문제 외에 버그가 있다.
드라이버 문제가 해결된다면 개인적으론 ARM64타겟으로 게임을 출시하고 싶다.
Windows 10 on ARM의 문제점
과도한 메모리 소모 문제
같은 코드의 ARM64빌드와 x86/64빌드를 각각 Surface Pro X와 x86/64머신에서 실행했을때 ARM64에서 메모리 소모가 1.5배쯤 된다. 2GB메모리를 소모하던 앱이 ARM64빌드로 3GB를 소모한다. 내 게임이 일단 그렇다. DirectX Runtime이나 GPU 드라이버에서 추가적으로 더 소모하는것이라고 추측한다.
DirectX용 GPU 드라이버 문제
- Draw() 호출이 몰리면 급격히 성능이 저하된다. draw call이 많아지면 심지어 Surface Pro 2보다도 더 느려진다. 유저모드 드라이버의 스케쥴링에 문제가 있다고 생각한다.
- DX11 Deivice를 멀티스레드로 억세스 할 경우 드라이버에서 크래시한다. ID3D11DeviceContext는 스레드 세이프하지 않다. 하지만 ID3D11Device는 스레드 세이프하다. 따라서 멀티스레드로 D3D리소스들을 동시에 생성하고 제거할 수 있다. 하지만 현재 Surface Pro X에서는 드라이버(아마도 유저모드 드라이버)에서 크래시한다. 다음과 같은 에러 메시지를 확인할 수 있다.
D3D11: Removing Device.
D3D11 WARNING: ID3D11Device::RemoveDevice: Device removal has been triggered for the following reason (DXGI_ERROR_DRIVER_INTERNAL_ERROR: There is strong evidence that the driver has performed an undefined operation; but it may be because the application performed an illegal or undefined operation to begin with.). [ EXECUTION WARNING #379: DEVICE_REMOVAL_PROCESS_POSSIBLY_AT_FAULT]
Exception thrown at 0x00007FFF8F6A4024 (qcdx11arm64um8180.dll) in MegayuchiLevelEditor_arm64_debug.exe: 0xC0000005: Access violation reading location 0x0000000000000028. - performace counter가 지원되지 않는다. Surface Pro X에서 그래픽 렌더링 상황을 GPUView로 분석을 하려고 시도했다. etl파일 캡처했는데 GPU정보가 전혀 나오지 않는다.스크린샷에서 볼 수 있듯 GPU정보가 전혀 나오지 않는다.
Windows Game bar도 작동은 하지만 GPU점유율이 0%로 출력된다. frame rate는 아예 출력되지 않는다. 드라이버 문제라고 생각한다.
GTX1660TI

Surface Pro X
결론
- 일반적인 CPU의 연산 – 산술연산, 메모리에서 읽고 쓰기, 이런 작업에서 SQ1프로세서의 ARM64 성능은 충분히 만족스럽다.
- spin lock 사용시 intel x86에 비해 크게 성능이 떨어진다. Critical Section사용등 멀티스레드 처리에 있어서 ‘나쁜 상황’에 처했을때 x86에 비해 성능이 크게 떨어진다.
- 아직은 intel x86보다 느리다. 클럭 주파수뿐 아니라 명령어 효율도 아직은 intel x86보다 떨어진다.
- 하지만 PC로 사용하기에 부족함이 없는 성능이다. CPU 성능은 intel x86에 비해 심각하게 뒤쳐지지는 않는다. 경우에 따라 x86보다 뛰어날때도 있다. 특히 GPU 성능은 인상적이다.
- 퀄컴의 GPU드라이버에는 문제가 있다. DirectX사용시 성능과 안정성 모두 문제 있다.
- 현세대 생산성 어플리케이션들이 ARM64로 빌드되어서 나와준다면 x86 디바이스에 비해 불편함 없는 작업환경을 제공할 수 있다고 생각한다.
- GPU드라이버가 개선된다면 x86 Surface Pro에서 돌리는 게임 정도는 무난히 돌릴 수 있을거라고 본다.
- x86 에뮬레이션 성능은 네이티브 ARM64에 비해 상당히 많이 떨어진다. Windows on ARM 생태계가 x86에뮬레이션에 의존해야한다면 미래는 없다.
ARM64로 포팅한 게임 플레이영상
[Project D Online on Surface Pro X]
[Voxel Horizon on Surface Pro X]
후일담
한국에 정식발매가 된 후 Surface Pro X를 처분했다. 이 리뷰의 마지막에 ‘Windows on ARM 생태계가 x86에뮬레이션에 의존해야한다면 미래는 없다.’라고 적었었다. 그리고 최종적으로 내린 결론은 이렇다.
‘Windows on ARM의 미래는 없다. Surface Pro X의 미래도 없다.’

자세한 자료 감사드립니다.
(결론 부분에 6이 두번 들어가 있어요)
좋아요좋아요
네. 그렇네요
좋아요좋아요
와 가려운 부분을 긁어주는 훌륭한 포스팅입니다….
긱벤치5 점수상으로 봤을때 arm 프로세서 성능이 많이 올라왔길래… windows on arm의 실태가 궁금했는데 벤치 감사합니다.
좋아요좋아요
그런데 이거 체감으론 인텔에 비해 훨씬 더 느립니다. 명령어 효율이 떨어지는데 클럭은 훨씬 더 낮으니까요. 드라이버도 품질이 떨어집니다.
좋아요좋아요
아직 컴파일러나 라이브러리가 ARM 환경에 최적화가 되지 않은 탓도 있을겁니다. 현재는 거의 황무지 수준이니까요.
좋아요좋아요
라이브러리는 뭐 쓴거 없고 거의 제가 짠 네이티브 코드로만 돌아갔고요. 그냥 ARM아키텍처가 아직 x86보다 느린거 맞습니다. 클럭소모측면에서도 그렇고 실제로는 훨씬 더 느립니다. 안그래도 명령어당 클럭을 더 소모하는데 x86쪽이 클럭주파수가 훨씬 높으니까요. 제 개인적으론 딱 결론을 냈는데 고성능이 필요한 곳에서 ARM CPU못씁니다.
좋아요좋아요
너무나 귀중하고 희귀한 벤치마크 자료네요. 감사합니다. 매우 중요한 레퍼런스가 될 것 같습니다. ㄷㄷㄷ
궁금한게 서피스 북2의 소모클럭이 데스크탑인 8700K보다 적게 나오는 경우가 왕왕 보이는데 왜 그런 건가요?
좋아요좋아요
측정에서 약간의 오차가 있을수 있고요. 데스크탑 CPU는 클럭이 높고 캐시메모리가 많은거지 명령어 효율이 노트북용 cpu보다 항상 높은것은 아닙니다. 클럭을 높이려고 명령어 효율을 희생하는 경우도 있으니까요. 클럭을 더 소모한다고 느린것이 아닙니다. 그 이상 클럭주파수가 높게 들어가면 더 빼른거니까요.
좋아요좋아요
아하 답변 감사합니다. 저는 노트북 CPU는 단순히 저클럭 데스크탑 버전인줄 알았는데 그런 단순한 게 아니었다는걸 이번에 잘 알고 가게 되네요.. 정말 천차만별이군요
좋아요좋아요
긱벤치 기준으로 SQ1의 빅코어와 4300U 점수가 거의 동일해서 4300U와 비교해 가면서 보고 있는데
벡터/매트릭스 연산 성능에서는 SQ1이 월등하다고 봐도 될까요? SQ1 빅코어 클럭이 3Ghz에 4300U 터보부스트 클럭이 2.9Ghz 더라구요.
좋아요좋아요
일단 다른 아키텍처의 cpu에서 긱벤치 결과는 좀 신뢰할 수 없다는 생각을 합니다. 이름만 같을뿐이지 ARM버전이랑 x86버전이랑 코드가 얼마나 다를지도 알수 없고요.
제 테스트에선 SQ1이 월등하다고까지 할만한건 아니고 앞서는 항목들이 있죠. 근데 그것도 SIMD쓸때 그렇고 SIMD를 안쓰면 ARM이 거의 항상 느립니다. 사실 실제 어플리케이션에선 테스트 상황처럼 SIMD를 잘 써먹을수는 없어요. SIMD쓸수 있는 산술처리 코드가 전체 코드중에 아주 극히 일부밖에 안되기 때문에 SIMD를 썼을때 약간 빠르다고 해서 그게 전체적인 성능으론 연결이 안됩니다. 그리고 4300U가 언제적 CPU인데 그거랑 최신의 SQ1프로세서를 비교한다는것도 좀 망신스러운거죠.
좋아요좋아요
아 제가 물어보고 싶었던 것은 벡터 매트릭스 테스트에서 SIMD 명령어셋을 쓰지 않고 모든 항목에서 SQ1이 지나치게 높길래 저도 좀 믿기지가 않아서
제가 혹시 자료를 잘못 해석한건지, 아니면 멀티쓰레드에서 이루어진 연산인가 싶어서요.. 제가 해석한 게 맞나요?
좋아요좋아요
일단 벡터 4칙연산에선 SQ1이 4300U보다 확연히 떨어지고요. 뒷장의 좀더 복잡한 테스트에선 전반적으로 SQ1이 4300U보다 빠른데요. 이건 SQ1이 빠르다기보다 4300U가 유독 떨어진다고 봐야겠죠. 다른 CPU들이랑 비교해도 확연히 떨어지니까요. 멀티스레드 아니고 싱글스레드입니다. 산술 연산 테스트에서 멀티스레드는 전혀 사용하지 않았습니다. 애초에 멀티스레드로 돌리면 정확히 클럭을 측정할수가 없어요.
좋아요좋아요
애초에 저 리뷰의 기술적 결론은 ‘ARM이 느리지 않다’니까 생각보다 빠른것도 전혀 이상할건 없죠. 리뷰 쓸때만 해도 저도 기대를 많이 했었는데요. 쓸만한 정도의 성능은 나왔으니까요. 문제는 딱 거기까지고, 현실적으로 ARM을 PC에서 사용하게 되면 x86에뮬레이션으로 쓸 상황이 90%이상이란겁니다. 리뷰 쓰고나서 4개월 정도가 지난 지금은 x86에뮬레이션을 벗어날 수 없다고 결론지었어요.
좋아요좋아요
상세한 답변 감사합니다. 이렇게 보니 인텔의 CPU도 장족의 발전이 있었네요..
기껏 윈도우 on ARM 제품이 나왔는데 x86에뮬에서 벗어나지 못하는 상황이 참 안타깝긴 하네요…
애플은 강제할 수 있을런지.. 아케이드를 보니 상당수 게임이 x86과 ARM을 둘 다 지원하는게 신기하더라구요.
맥에서 실행해보니 터치 인터페이스가 그대로 적용되어있고 추가로 키보드와 컨트롤러를 지원하던데
사실상 iOS 게임을 에뮬에서 돌리는것처럼 별 변화 동일한 UI가 적용되어 있더군요.
에뮬은 아닌것 같던데 네이티브로 강제시킬 수 있었던게 신기하긴 해요
좋아요Liked by 1명
SQ1에서 SSE4 까지 애뮬레이트 할 수 있다는 게 사실인가요? 아직 SSE4 명령어 특허가 만료(기한 20년)되지 않아서 2020년에 애플이 ARM 사용한다고 해도 SSE3 까지가 한계라서 64Bit 애뮬레이트 못할 거로 봤는 데 말이죠. 어차피 인텔 팬티엄 시리즈는 AVX 명령어가 아에 제거된 상태로 팔아먹는 지라 SSE4를 애뮬레이트 할 수 있으면 충분히 ARM에서도 X86 64Bit 프로그램들 애뮬레이트는 할 수 있겠네요.
좋아요좋아요
sse4 에뮬레이션이 안됐으면 제가 짠 코드가 에뮬레이션으로 안돌았을테니까요. 지금 다시 확인해보고싶진 않고 당시에 꽤 놀랐던걸로 기억합니다. 근데 돌아만 가는거지 성능상의 이득은 전혀 없었던걸로 기억합니다. x64에뮬레이션 문제가 라이센스 때문이라고 생각진 않습니다. 32비트 에뮬레이션도 문제가 많은데 64비트를 논할 처지가 아니기 때문이라고 생각합니다. 32비트 에뮬레이션도 제대로 돌아가는게 아닙니다. 정상 작동 못하는 경우가 많아요. 사실 x64에뮬레이션 지원예정이란 기사는 여러번 나왔습니다. 작업은 하고 있을겁니다. 다만 Windows on ARM자체가 괸심대상이 아닙니다. azure가 최우선인 MS는 애플과는 입장이 다르거든요.
그리고 보통 어플리케이션 시작할때 avx/sse지원 여부를 체크부터 하고 일반코드로 갈지 확장명령 코드로 갈지 결정하기 때문에 sse지원여부는 문제가 아닙니다. x64명령어체계가 sse를 기본으로 가져갑니다만 그것도 sse2까지고요.
좋아요좋아요
친절한 답변 감사합니다. 이번 애플 ARM 전환 때문에 해당 포스팅 보게 되었는 데 블로그에 참 유익한 글이 많더라고요. 내년에 한번 애플 ARM 시스템 구입해볼 생각인 데 퀄컴은 확실히 압살하는 애플 A시리즈라서 어떤 결과 나올 지 기대 됩니다.
일단 애플이 직접 소유권 가지고 있는 프로그램들은 ARM 네이티브로 포팅 될 거고 MS하고 어도비쪽은 포섭이 끝난 거 같습니다. 네이티브 게임은 기존 아이폰. 아이패드 iOS 앱이나 애플아케이드가 그 역활을 담당하고 고성능 AAA 타이틀쪽은 X클라우드로가 담당할 거 같은데 과연 어떻게 될지 기대되네요.
솔직히 8CX가 스냅드래곤 855 기반이라서 진짜 별 기대 안했거든요. 거의 예쁜 쓰레기급으로 봤었습니다.
좋아요좋아요
Surface Pro X의 경우 ARM64네이티브 코드의 경우는 성능은 문제가 안됩니다. 문제는 ARM64앱이 거의 없다는것과 드라이버 지원입니다. 모든 업체가 ARM64용 드라이버로 포팅을 하지는 않으며, 포팅을 한다해도 십년 넘게 검증된 x86코드가 아니기 때문에 무슨 문제가 있을지 모릅니다. 결정적으로 Windows on ARM은 MS내부에서도 그닥 관심사가 아니라서 문제해결이 빠르게 이루어지고 있지 않습니다. 저 리뷰를 쓰고나서 몇개월을 지켜본 결과 얘네들은 잘 해볼 생각이 없다고 결론을 내렸습니다. 그래서 최근에 Surface Pro X도 처분해버렸고 진행중인 프로젝트도 더 이상 ARM64타겟으로 빌드하지 않습니다. 뭐 애플의 경우는 회사 전체적으로 총력을 기울이고 있으니 훨씬 낫겠죠.
좋아요좋아요
directx 대신 vulkan 을 사용하면 어떤가요?.
좋아요좋아요
DX/911과 OpenGL은 구조적으론 비슷합니다.
여기서 소위 차세대 api로 추가된 것이 DX12, Vulkan, metal이고요. 얘네들은 사촌간입니다. 컨셉이나 드라이버 하위 레이어의 구현이나 엄청 비슷합니다. 따라서 즉 DX12가 제대로 작동하지 않으면 vulkan도 거의 제대로 작동하지 않습니다.
Windows에선 게임이든 일반 어플리케이션이든 DX11이 표준입니다. 따라서 퀄컴에서도 DX11까지만 어떻게든 맞춘걸로 보이고 DX12는 작동은 하되 정상작동하지 않습니다. 사실 DX12는 nvidia, AMD의 dGPU가 아니고선 내장 GPU계열은 정상지원하지 못하는 경우가 대부분입니다. 텍스처가 안나온다든가 비동기 피처를 지원하지 않아서 엄청나게 느리던가 그런식입니다. 돌아만 가는거죠.
DX9/11, OpenGL까지도 API 구조가 비슷해서 상호 포팅하는데 그리 어렵지 않습니다만 DX11->DX12가는건 렌더러 새로 만드는 수준으로 일이 큽니다. DX11 -> Vulkan 가는건 더 힘들고요. 구조가 완전히 다른데 데이터 타입과 함수 이름마저 완전히 다르니까요.
제 엔진은 DX12까진 지원하지만 Vulkan은 지원하지 않습니다. Vulkan은 안드로이드 진영이나 리눅스 진영에선 밀고 있는데 게임계 표준은 아닙니다.
DX12와 Vulkan은 구조가 매우 비슷하고 어차피 드라이버 구현의 아랫쪽 레이어는 DX12와 Vulkan 모두 같은 코드를 쓸겁니다. 따라서 DX12 성능이나 Vulkan이나 비슷하게 나올거란 얘기죠.
제가 DX12를 한 1년 이상 집중적으로 파봤는데 어지간해선 DX11보다 성능은 안나옵니다. 제가 코드를 못짜서 그런게 아니고 실제 상용게임들 나온거 비교해봐도 DX12로 돌릴때 DX11보다 느린 경우가 대부분입니다.
Vulkan이 Open GL보다 빠른 벤치는 많이 보고 되는데, OpenGL파들에겐 미안한 얘기지만 OpenGL이 워낙 낡은 API라 원래 성능이 안나옵니다. 그러니 Vulkan으로 포팅만 했는데 성능이 높아졌다는 얘기는 말이 됩니다. 단 DirectX에는 해당사항이 없는 얘기입니다.
그러니 제 입장에선 그거 Vulkan성능이 궁금해서 또 Vulkan버전 엔진을 만들어야할 이유가 없죠.
정리하자면,
아마 Surface Pro X에서 Vulkan으로 돌리면 DX11/12보다 낫지 않겠느냐는 의도로 질문을 하신거 같은데
1. DX12도 제대로 돌지 않는 상황에서 Vulkan이 일단 제대로 작동할거라고 보지 않습니다. 이건 하드웨어 문제는 아니고 GPU드라이버 문제입니다.
2. DX12가 제대로 돌지 않지만 돌아가는걸로만 비교할때 DX11보다 압도적으로 느립니다. 이건 모든 내장 GPU칩에서 공통적으로 나타납니다. Vulkan은 DX12와 구조가 매우 비슷하므로 기대하는 성능은 DX12수준이고 그럼 DX11보다 느리겠죠.
3. 결정적으로 그걸 비교하려면 Vulkan버전 렌더러를 또 만들어야하는데 그럴 여럭도 하고 싶은 마음도 없습니다. Vulkan은 저한텐 전혀 관심사가 아니거든요.
좋아요좋아요
감사합니다
좋아요좋아요
위 글을 읽고나니 스타시티즌의 “스타엔진”이 대단하다고 생각되네요. 처음에 스타시티즌의 개발을 시작했을땐 32비트였다가 64비트로 전환하고 dx11을 사용 중인데 곧 vulkan/dx12로 엔진 자체를 개조한다고 하네요
좋아요Liked by 1명
아니 뭐 의욕만 있으면 하죠. 제 엔진도 최초엔 dx7에 32비트였는데 지금은 dx11/dx12에 64비트니까요. 다만 그렇게 열심히 업데이트하는게 돈하고 연결되는건 아니라서 업체들이 미온적인거죠.
좋아요좋아요
와 포스트 정말 잘봤습니다 감사합니다
팬리스 윈도우 피씨를 가지고 싶었는데
10년뒤에 다시 알아보겠습니다 ㅋㅋㅋ
좋아요좋아요
팬리스를 알아보신다면 서피스GO 2가 있습니다. 그리고 서피스 프로 7에도 팬리스가 있을거에요.
좋아요좋아요
감사합니다 양질의 리뷰 덕분에 x를 거를 수 있었습니다..
좋아요좋아요
잘 거르셨습니다.
좋아요좋아요
좋은 글 잘 보았습니다.
저도 ARM은 surface RT이후로 쳐다도 안봤는데, 이번 맥북에 ARM이 들어간다길래 관심있게 지켜보고 있네요 ㅋㅋ
좋아요좋아요
데스크탑 수준의 high클럭에 대해선 전 여전히 회의적인데요. 게임 안하고 노트북 기준이면 앱지원만 되면 ARM으로 갈아타도 된다고 생각합니다. windows생태계에선 무리고 맥은 반드시 돌아가야할 앱 개수가 적으니 할만하겠죠.
좋아요좋아요
지금 M1 벤치마크랑 분석을 보니 코어 성능에서 종전의 데스크탑 칩셋을 훌쩍 뛰어넘었더군요
그것도 훨씬 낮은 3.2ghz 클럭에서요
아난드텍 분석 결과를 보면 A14 빅코어는 시중의 그 어떤 코어보다 거대한 디자인을 가졌다고 하네요
그래서 굳이 데스크탑 수준의 클럭에 집착할 필요 없이 높은 성능을 뽑아낼 수 있는것 같습니다
좋아요좋아요
1년 전 처음 들였다가 64비트 미지원의 한계가 치명적이어서 처분했다가 어제 다시 들였습니다.
10에서 약속한 지원은 없었고, 결국 64비트 프로그램은 윈도우11로 올려야 가능하더군요.
만족할만한 퍼포먼스는 아니지만 그렇다고 극도의 불만족을 불러일으키는 기기도 아니기에…서피스 프로7 대신 선택했습니다.
저의 선택이 어떨지 모르겠으나 저의 간단한 용도를 행해줄 기기로는 나름이라도 괜찮길…
서브 기기라 간단한 코딩이나 이북리더로 사용할 것 같습니다.
좋아요좋아요
gpu드라이버에 아직도 문제가 있더군요. 기술적 호기심에서 저도 아직 관심이 있습니다만 너무 비쌉니다.
좋아요좋아요
글 정독했습니다. 그리고 잘 봤습니다 🙂
곧 있으면 출시될 8CX gen3 채용한 랩탑을 구매하려고 합니다.
전 그냥 윈텔이 pc진영 다 먹기전, 윈도우 95 출시되기 전 처럼
다양한 회사들이 다양한 플랫폼으로 경쟁하던 춘추 전국 시대왔으면 좋겠네요.
맥북 에어 사용자들은 windows를 원하고
기존 x86 사용자들은 arm의 저전력과 팬리스를 원하고
엑시나 퀄컴같은 arm 프로세서 채용한 제품들이 woa와 wsl 결합되면
많이 잼있어질것 같아요.
좋아요좋아요
지금까지도 서피스 프로x를 사용중인 지인들로부터 얻은 정보에 의하면 여전히 사용할 수 없는 수준이라고 알고 있습니다. 도시락 싸들고 말리고 싶지만 맘에 들면 사는거죠.
좋아요좋아요