서론
2019년에 ‘프로그래머의 관점에서 본 Surface Pro X 벤치마크‘라는 글을 작성했었다.
이후로 2년 반 정도가 지났다. 여전히 Windows on ARM에 관심을 가지고 있지만 Surface Pro X를 비롯한 Windows on ARM의 하드웨어 생태계는 그다지 발전하지 않았다. Windows on ARM의 표준적인 칩인 퀄컴의 8cx, 7cx칩의 GPU드라이버는 여전히 불안정하다.
Windows on ARM생태계가 정체되어있는 동안 애플에서 ARM기반의 자체 프로세서와 새로운 Mac하드웨어를 발표했다. 애플은 x86-> ARM으로의 이행에 진심이었고 상당한 성과를 거두었다. 이제 Mac 생태계에서는 x86이 아닌 ARM명령어세트가 주류이다.
‘MS는 Windows on ARM에 대해서 완전히 잊고 있는가? 클라우드만 팔아먹겠다는것인가?’ 라고 생각하고 있는 이 시점에 Visual Studio 2022 ARM64 빌드가 preview로 릴리즈 되었다.
이전에 Windows on ARM디바이스에서 x64빌드의 Visual Studio를 에뮬레이션으로 실행하는 것은 불가능에 가까웠다. 돌아는 가지만 체감 10배는 느리고 메모리도 미친듯이 처먹어서 도저히 사용할 수 없었다. 안정성도 극히 떨어졌다.
개인적으로 ‘그 기기에서 돌아갈 소프트웨어를 직접 개발할 수 없는 장비가 무슨 컴퓨터인가?’ 라고 생각한다. 그래서 Visual Studio가 네이티브로 돌아가기 전까지는 Windows on ARM디바이스를 다시 구입하지 않을 생각이었다. 그런데 이제 ARM64디바이스에서 직접 ARM64코드를 편집하고 빌드하고 디버깅 할 수 있다는 것이다. 이건 굉장하다. 그래서 Windows on ARM디바이스를 다시 물색하기 시작했다.
마침 진행하던 프로젝트가 소강상태에 접어들었다. 무엇을 만들어야 하는지 고민을 하기 시작했다. 모바일 개발을 하기는 해야겠기에 안드로이드와 iOS를 저울질했다. iOS개발을 하려면 어차피 Mac이 필요하다.
m1 Mac에서 Parallels desktop을 사용하면 Windows 11 on ARM을 돌릴 수 있다고 이미 알고는 있었다. 그렇다면 m1 Mac한 대만 있으면 iOS/macOS개발과 Windows on ARM개발을 동시에 할 수 있겠네? 라는 생각이 들었다. 물론 어느 정도로 잘 돌아갈지는 알 수가 없다.
내가 원하는 벤치마크는 없다.
Parallels위에 올린 Windows on ARM에서 DirectX가 얼마나 정상적으로 돌아가는지, VS2022로 코드작성/디버깅이 정말 가능한지.
Surface Pro X때와 마찬가지로 직접 테스트 해보는 수 밖에 없다. 이 참에 소문의 그 뛰어나다는 m1이 정말 그렇게 빠른지 검증해 보고 싶다.
물론 일반적으로 가상화 솔루션에선 원래 하드웨어의 성능을 100% 얻지는 못한다. 하지만 ‘프로그래머 관점에서의‘ m1의 성능은 가늠해 볼 수 있다고 생각했다.
그래서 테스트를 위해 m1 Mac mini를 구입했다. 이제 테스트를 해보자!
테스트 목표 & 방향
m1 CPU성능이 소문대로 그렇게 뛰어난지 궁금했다.
메모리 억세스가 빠르다고 듣기는 했다.
그런데 클럭당 명령어 효율도 뛰어날까? 난 애플 팬은 아니기에 애플이 CPU기술에서 근본적으로 크게 앞선다고 생각지는 않는다.
또한 GPU성능이 RTX급이라거나 그 이상이라는 소리들도 하는데 그 역시 믿을 수 없다. 기존 GPU업체들이 바보가 아니다.
사실 CUDA와 OpenCL, Vulkan을 사용할 수 없다는 점에서 이미 GPU의 경쟁령은 0에 가깝다고 생각한다. 하지만 이런 점은 무시하고 그래픽스 성능만을 확인해 볼 것이다.
따라서 테스트할 항목은 크게 두 가지.
- CPU 성능(특히 클럭당 명령어 효율)
- GPU의 그리기 성능(삼각형 레스터라이즈, shader성능)
테스트 코드는 2019년에 Surface Pro X 리뷰 글을 작성할 당시에 작성해 두었다. 이후로 거의 수정하지 않았다. 그 코드를 그대로 사용할 것이다.
성능에 민감한 수학함수들의 경우 x86/x64에선 SSE/AVX를 사용하고 있다. ARM64아키텍처인 Surface Pro X/m1 Mac에서는 Neon(ARM64용 SIMD명령셋)으로 작성된 코드를 사용한다.
2019년에 직접 개발중인 게임 VOXEL HORIZON으로 테스트를 했었다. Surface Pro X의 렌더링 성능은 괜찮은 수준이었다. 당시엔 게임 렌더링 성능 보다는 게임 내에서의 Lightmap baking성능을 주로 테스트했다.
이번에도 VOXEL HORIZON의 플레이 테스트를 진행한다. GPU렌더링 성능을 보는 것이 중요하므로 Lightmap baking테스트는 실시하지 않는다.
VOXEL HORIZON의 전체 프로젝트는 ARM64 빌드를 유지하고 있으므로 추가 코드를 작성할 필요는 없다.
Surface Pro X는 2020년 초에 처분했다. 그래서 이번 테스트에서는 지인에게 벤치마크 테스트 툴과 게임의 바이너리를 보내주고 테스트를 부탁했다. 그러니까 지인을 통해서 받은 테스트 결과이고 직접 테스트하지는 않았음을 밝혀둔다. CPU성능의 테스트 결과는 2019년 당시와 거의 다르지 않다.
테스트방법
- m1 Mac mini에 Parallels desktop을 설치하고 Window 11 on ARM을 설치한다.
- Windows 11 VM에 8개 코어와 램 10GB를 할당한다.
- 툴체인으로는 Visual Studio 2022 17.2.6을 사용한다.
- 직접 개발한 성능 테스트 툴을 데스크탑 pc에선 x64빌드로, Mac mini와 Surface Pro X에서 ARM64빌드로 실행한다.
- 직업 개발한 게임을 데스크탑 pc에선 x64빌드로, Mac mini와 Surface Pro X에서 ARM64빌드로 실행한다.
테스트 전에 미리 짚고 넘어갈 점
Q: 가상화된 환경에서 m1의 성능을 정확하게 측정할 수 있는가? 가상화된 환경이므로 원래 성능보다 떨어지게 측정될 수 있지 않을까?
A: 가상화는 에뮬레이션이 아니다. 특정 명령어에 트랩을 걸어서 특정 상황에서 호스트 OS가 제어권을 선점하는 것이 가상화의 핵심이다. 일반적인 유저모드 명령어들은 후킹 대상이 아니다.
테스트 코드들은 커널로 진입해야하는 시스템 콜을 전혀 사용하지 않는다.
또한 스레드 퀀텀이 시분할 스케쥴링 되는 동안 충분히 실행될 수 있다. 따라서 가상화로 인한 성능 저하는 없다고 본다. 비교군으로 사용한 Xeon VM은 Azure상에서 돌아가는 가상머신이다. 그럼에도 불구하고 리얼머신과 차이없는 성능을 보여준다.
단 멀티스레딩 테스트는 스레드를 대기시키고 깨우기 위해 시스템 콜을 사용한다. 가상화로 인한 성능 저하가 있을 수 있다. 그러나 테스트 결과를 보면 이로 인한 성능저하는 거의 없어보인다.
게임 플레이 테스트는 GPU드라이버의 영향을 받는다. 가상화 솔루션에 따라 GPU성능은 다르게 측정될 수 있다. Parallels의 GPU드라이버의 구현에 따라서 성능 차이가 발생할 수 있다.
다만 가상화 솔루션으로 인한 성능저하가 큰지 여부는 어느 정도 확인할 수 있다.
가상화 솔루션으로 인한 성능 저하가 크다면 저해상도일때, 고해상도일때의 프레임 레이트 차이가 크지않다. 해상도에 상관없이 성능이 나쁘게 측정된다. 그러나 테스트 결과를 보면 m1 Mac에서의 프레임 레이트는 전적으로 해상도에 의존한다. 해상도가 낮을때는 좋은 프레임 레이트를 보여주지만 해상도가 높아지면 극적으로 성능이 떨어진다.
가상화 솔루션으로 인한 성능 저하가 없다고 보장할 수는 없다. 그러나 가장 큰 변수는 해상도이므로 적당히 낮은 해상도에서 테스틀르 진행하면 GPU성능 측정에 무리가 없다고 판단한다.
산술연산 테스트
싱글스레드로 테스트한다. 소요시간을 측정하지 않는다. 소모한 클럭을 측정한다. 테스트에 사용된 프로세서들은 모두 작동 클럭이 다르다. 동일한 클럭이 인가되면 소모클럭이 적은 시스템이 더 빠르다.
– big.LITTLE Architecture on SQ1 Processor
여기서 짚고 넘어가야하는 것이 있다. SQ1프로세서는 다른 ARM AP들과 마찬가지로 big.little아키텍처를 사용한다. 고성능의 4개의 Big Core와 저성능의 4개의 little Core로 구성돼 있다. big core는 Gold Core라 부르고 little core는 Silver Core라 부른다. 클럭만 다른게 아니고 명령어 효율 자체가 다르다.
little core가 0,1,2,3번, big core가 4,5,6,7번이다. 8개 동시에 사용될 수 있다. 산술 테스트에서는 1번,5번 코어를 사용한다.
– big.LITTLE Architecture on M1 Processor
wiki문서에 따르면 m1 프로세서는 고성능의 “Firestorm” 코어 4개와 저성능의 “Icestorm” 코어 4개를 가지고 있다고 한다. SQ1프로세서의 경우 silver코어와 gold코어 번호가 지정되어있고 어느 코어를 지정하느냐에 따라서 정확하게 성능이 다르게 측정된다. m1의 경우 0번부터 7번까지 코어 번호를 바꿔가며 지정해봤으나 모두 같은 결과가 측정되었다.
구글검색을 통해 다음과 같은 글을 발견했다. float연산을 하면 고성능 코어쪽으로 전달이 된다고 한다.
https://www.tomshardware.com/news/apple-m1-icestorm-delivers
어쨌든 몇 번을 테스트 해봐도 모든 코어에 대해 거의 같은 결과를 얻었다. 고성능코어와 저성능 코어를 특정할 수 없었기 때문에 고성능 코어와 저성능 코어를 구분하지 않고 모든 코어에서 다 실행해보고 가장 높게 나온 수치를 기록했다.
– SIMD(Single Instruction Multiple Data)
명시적으로 SIMD코드를 작성하지 않고 표준적인 C코드를 작성할 경우 컴파일러는 자동으로 SIMD처리를 해주지 못한다. 단 SIMD 명령어셋의 싱글 명령들과 SIMD용 레지스터는 사용한다. 기존의 FPU를 사용하는것보다 빠르다.
이 테스트에서 SIMD로 표기한 경우 명시적으로 SIMD코드를 작성한 경우이다.
No SIMD로 표시한 경우 표준적인 C코드로 작성했음을 의미한다. 그러나 컴파일러는 FPU대신 SIMD레지스터와 명령어를 사용하므로 그래도 FPU를 사용하는것보다 빠르다. 따라서 SIMD코드와 성능 차이가 거의 없거나 때때로 더 빠를 수 있다.
x86/x64용 SIMD코드는 SSE를, ARM64용 코드는 Neon을 사용했다.
x,y,z,w 4차원 벡터에 대한 4칙연산 테스트
4칙연산 테스트다. 메모리 절약을 위해서 게임에선 3차원 벡터(float3)를 주로 사용한다. float3타입은 메모리에서 한번에 읽어들일수 없고 한번에 써넣을수 없다. 따라서 메모리에 읽고쓰는 동작에서 추가적인 비용이 발생한다. 이 테스트는 단순한 산술연산을 얼마나 빠르게 하는지 테스트가 목적이기 때문에 4차원(float4)벡터를 사용했다.
덧셈과 뺄셈은 기본적으로 같은 연산이므로 뺄셈은 따로 테스트하지 않았다.

Add or Sub Or Mul or Div 테스트는 같은 오퍼레이션을 반복하는 대신, 전달된 벡터배열의 인덱스에 따라 4가지 연산으로 분기한다. 분기하는 상황에서 캐시미스를 유도하고 분기예측에 혼란을 주기 위함이다.
intel x86이 가장 빠르다.
SQ1과 m1은 나눗셈을 제외하고 거의 비슷하다. SIMD(neon)사용시 근소하게 SQ1이 빨라보인다.
Vector 및 Matrix 연산 테스트
게임 프로그래밍에서 많이 사용하는 함수들이다. 내 게임에서 실제로 사용하는 함수들을 사용했다.
TransformVector_xxxx()함수들은 float3 스트림을 배열형태로 전달하기 때문에 함수호출 비용은 무시해도 좋다. 그러나 Matrix곱셈이나 Normalize()함수, CrossProduct(), DotProduct()등은 함수 한번에 한번의 오퍼레이션을 수행하므로 소모된 클럭에는 함수 호출 비용이 포함되어있다.

산술연산 테스트 결론
intel x86이 가장 빠르다. 명령어 효율에서 x86이 가장 앞선다.
4칙연산 속도는 비슷하지만 수학함수의 실행속도에서 SQ1이 m1보다 명백히 빠르다.
m1의 geekbench결과가 알려지고나서 많은 사람들이 m1의 모든 측면에서의 성능이 절대적으로 우월할것이라고 생각했지만 결과는 그렇지 않다.
계산이라는 측면에서 m1은 기존 프로세서들에 비해 결코 우월하지 않으며 오히려 떨어진다(그 느려터지다 하는 SQ1보다도).
memcpy 테스트
VC++의 memcpy()함수를 사용해서 1GiB의 메모리를 복사한다. 여기서는 멀티 스레드를 사용한다.
1GiB의 메모리를 활성화된 스레드 개수로 나눠서 동시에 모든 스레드가 카피를 진행한다.
스레드간 동기화는 필요하지 않으므로 lock은 사용하지 않는다.
참고로 2019년 포스팅 당시 memcpy()성능에 의문을 갖는 이들의 많은 문의를 받았다. 이후 x64용 8/16/32바이트 카피 함수를 어셈블리어로 작성해서 모두 테스트 했고 가장 안정적으로 빠른 속도를 보장하는 코드는 VC++의 memcpy()함수임을 확인했다. 실제로 memcpy()함수 내부를 뜯어보면 풀 어셈블리어로 작성되어있으며 사이즈에 따라서 1+4+8 , 2+8+16 등 가장 적절한 레지스터와 카피 명령조합을 사용하도록 되어있다. https://youtu.be/wv7-Ym3GYEk?t=10577
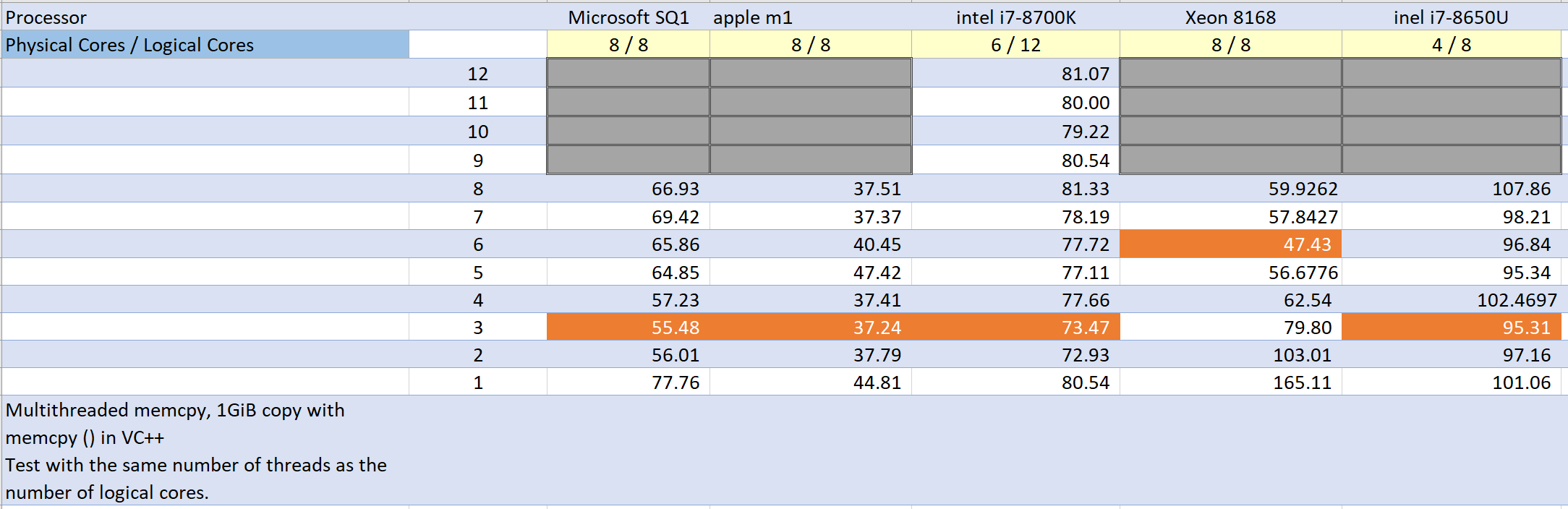
memcpy 테스트 결론
m1 이 가장 빠르다. ‘빠른 메모리 억세스‘가 m1성능의 거의 모든 것을 말해준다.
다만 이것은 CPU아키텍처의 획기적인 변화가 아니다. CPU, 메모리, 저장소의 물리적 배치를 변경해서 얻은 성능 향상이다. 즉 합리적인 접근일지는 모르나 다른 CPU회사들을 앞서는 외계인의 기술을 가진게 아니라는 거다.
Multithreading 응답성 테스트
context switching 비용, 스레드간 동기화에 필요한 lock의 비용이 얼마나 높은지를 측정하는 테스트이다.
처음 내 게임과 툴 코드들을 ARM64로 포팅했을때 성능이 만족스럽지 못했다. 멀티스레드로 돌아가는 툴들에서 특히 성능이 나빴으므로 ‘ARM64에서 멀티스레드 응답성에 문제가 있지 않을까’ 라고 추측했다.그래서 이 테스트를 진행했다.
기본적으로 이 테스트는 4바이트 변수가 특정 값에 도달할때까지 여러개의 스레드가 경쟁적으로 값을 증가시킨다. 다만 각 테스트 별로 동기화를 위한 방법이 다르다.
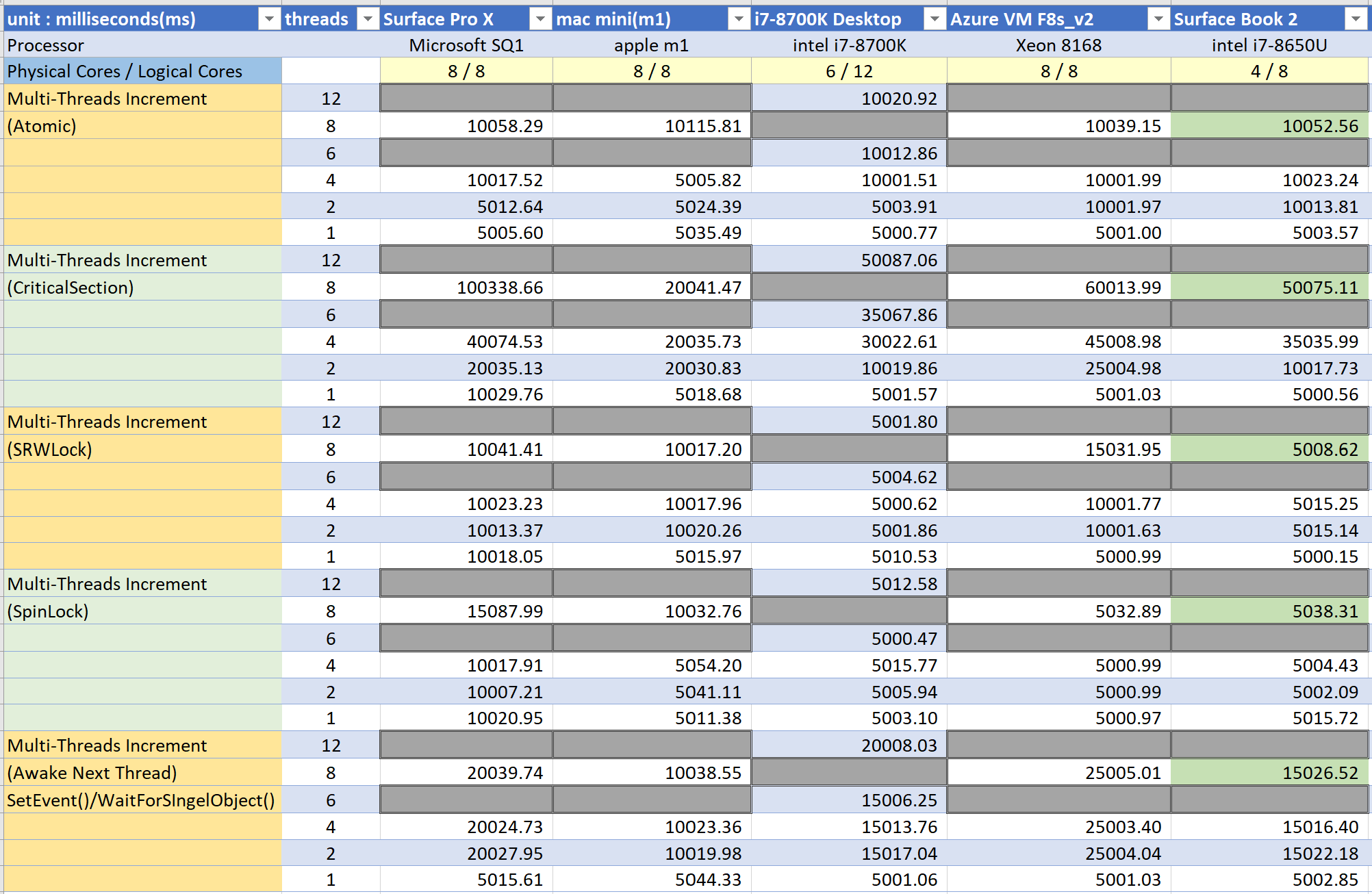
atomic increment테스트는 lock객체를 사용하지 않고 4바이트 변수값을 증가시키는 테스트다. x86이라면 어셈블리어로 lock inc dword ptr[mem] 한 줄로 표현된다.
스레드 수에 관계없이 m1 프로세서는 일정한 성능을 보여준다. atomic연산에 있어서 패널티가 없어보인다.
Critical Section 테스트는 critical section으로 락을 걸고 변수값을 증가시킨다. critical section으로 감싼 코드 블럭에 다른 스레드가 먼저 진입한 경우 늦게 진입하는 스레드는 먼저 진입한 스레드가 critical seiction에서 나갈때까지 스케쥴링 되지 않는다. 즉 wait상태가 된다. 다시 스케쥴링 될때는 지연시간이 걸린다. 스레드 개수가 많아지면 더욱 성능이 저하된다. 매우 나쁜 상황이다. 이 상황에서 각각의 CPU들이 얼마나 성능이 저하되는지를 알고 싶었다.
이런 상황에서 SQ1프로세서의 성능이 크게 저하되는것으로 보인다. 만약 critical section이나 비슷한 방식의 동기화를 많이 쓰는 어플리케이션이라면 꽤 성능저하가 있을 수 있다.
반면에 같은 ARM 명령어세트를 사용하는 사용하는 m1은 Critical Section을 사용하는 경우에도 상당히 좋은 응답성을 보여준다.
SRWLock은 최근 많이 쓰이는 경량 lock이다. 내부적으로 spin lock으로 구현되어있다. 매우 효율적인 코드로 작성되어있다. spin lock만 사용하면 먼저 진입한 스레드가 장시간 빠져나오지 않을 경우 진입을 기다리는 스레드가 바쁘게 작동하기 때문에 전체적으로 시스템 성능을 떨어뜨릴 수 있다. SRWLock은 이에 대한 대비가 되어있다. 진입을 대기하는 스레드는 일정 회수 이상 진입에 실패하면 Wait상태가 되므로 성능저하를 피할 수 있다.
스핀을 도는 도중에 작업을 끝내면 스레드가 wait될 일이 없다. 따라서 클럭이 높은 시스템이 테스트에서 좋은 결과를 얻을 가능성이 높다. 실제로 클럭이 높은 편에 속하는 i7 8700K와 i7 8650U프로세서의 응답성이 좋게 측정된다.
m1과 SQ1의 응답성은 큰 차이가 없어보인다.
spin lock테스트는 내가 직접 만들어서 사용하는 spin lock을 이용해서 동기화한다. SRWLock과 비슷하지만 먼저 진입한 스레드가 장시간 빠져나오지 않을 경우에도 대기중인 스레드가 wait하지 않는다. 명백하게 몇백 클럭 이내로 끝날 정도의 코드블럭을 동기화하는데 사용한다. 스레드가 코드블럭을 빠르게 빠져나온다면 SRWLock보다 훨씬 빠르다.
x86에서는 lock cmpxchg명령을 사용하며 spin lock구현 자체는 SRWLock과 거의 같다.
x86의 성능이 균일하게 뛰어나고 m1도 좋은 축에 속한다. SQ1은 2배 정도 느리다. 2019년 리뷰에서 이 문제를 지적한 바 있다.
spin lock사용시 SQ1 ARM64의 성능저하 , 상대적으로 m1의 성능우세
spin lock(SRWLock을 포함하여) 사용시 SQ1의 성능이 x86, m1보다 많이 떨어진다.
2019년에 처음 이 테스트를 수행했을 당시엔 ARM에서의 CAS(Compare And Swap)구현이 loop를 돌면서 시도하는 방식이고 그에 따라 코드도 길어지기 때문에 더 느린거라고 생각했다. x86의 경우 lock cmpxchg 명령어 한줄로 끝나지만 내부적으론 루프를 돌 것이다. 그럼에도 불구하고 x86의 방식이 더 효율적일것이다. 그렇게 생각했다.
그러나 다른 종류의 atomic연산에서는 SQ1이 딱히 느리지는 않았다. 따라서 코드 길이의 문제는 아니다. 그리고 이번에 m1을 테스트하고 코드길이 문제가 아니라는 점이 확실해졌다. 동일한 바이너리를 실행하지만 m1이 SQ보다 훨씬 빠르다.
(Awake Next Thread)테스트는 wait 상태의 스레드가 깨어날때 얼마나 지연시간이 있는지를 테스트한다.
예를 들어 3개 스레드로 테스트하는 경우,
각각의 스레드들이 서로 꼬리를 물고 작동된다. 이것은 일종의 라운드 로빈이다.
- 0번 스레드는 변수값을 증가시킨 뒤 SetEvent(event[1])을 호출해서 1번 스레드를 깨운다.그리고 WaitForSingleObject(event[0]);를 호출해서 대기상태에 들어간다.
- 1번 스레드는 변수값을 증가시킨 뒤 SetEvent(event[2])를 호출해서 2번 스레드를 깨운다.그리고 WaitForSingleObject(event[1]);를 호출해서 대기상태에 들어간다.
- 2번 스레드는 변수값을 증가시킨 뒤 SetEvent(event[0])를 호출해서 0번 스레드를 깨운다.그리고 WaitForSingleObject(event[2]);를 호출해서 대기상태에 들어간다.
- 변수값이 목표값에 도달할때까지 이를 반복한다.
결과를 보면 m1프로세서가 가장 좋은 응답성을 보여준다. 가상화된 OS에서 작동한다는 점을 감안하면 놀라운 결과이다.
Multithreading 응답성 테스트 결론
다수의 스레드가 경쟁적으로 lock을 획득하려고 하는 경우(spin lock을 포함하여)에 SQ1프로세서는 intel x86보다 성능이 떨어진다. 반면에 m1은 intel x86에 비해 딱히 성능이 떨어지지는 않는 것으로 보인다. 대기중인 스레드를 깨우려고 할 때는 m1의 반응이 가장 빨랐다.
이전의 테스트에서 SQ1은 멀티스레드 응답성이 많이 떨어지는것으로 보였지만 같은 ARM계열인 m1은 훨씬 좋은 성능을 보여준다.
다수의 코어를 총동원하는 작업에서 스레드 간의 동기화가 필요하다면 m1 프로세서는 좀더 선형에 가까운 성능향상을 보일 수 있을것으로 추측한다.
게임 렌더링 테스트
개발중인 VOXEL HORIZON의 x64, arm64 빌드로 렌더링 성능을 테스트했다.
서버의 개인맵에 접속 후 정해진 vxl파일을 업로드 하고 거의 같은 카메라뷰에서 프레임 레이트를 측정하였다.
DirectX 11, 1920×1080해상도에서 테스트하였다.

게임 렌더링을 위한 m1의 GPU성능
기대에 많이 못미친다.
처음에는 parallels의 GPU드라이버에 문제가 있다고 생각했다. 일반적으로 그래픽 드라이버로 인한 성능 문제가 있다면, 렌더링 되는 오브젝트 개수(draw call)이 많아질수록 성능이 크게 떨어진다. 이 경우 화면 해상도의 크기에 상관없이 프레임 레이트가 떨어진다. 그러나 Mac mini에서의 테스트 결과를 보면 절대적으로 해상도에 의존한다. 캐릭터 1명에 하늘만 렌더링하고 있어도 해상도가 높아지면 성능이 크게 떨어진다. 하늘 렌더링은 절대적으로 shader코드에 의존하며 draw call이 매우 적다.
1200×800정도의 해상도라면 꽤 플레이할만 하다. 그러나 1920×1080정도만 되어도 플레이 하기 어려울 정도로 느려졌다. 따라서 테스트 결과는 실제 GPU성능을 반영하고 있으며 m1의 GPU는 게임 렌더링에 적합하지 않다고 본다.
Windows on ARM타겟의 게임 개발을 위해서는 가장 적합한 디바이스
그럼에도 불구하고 m1 Mac은 현존하는 Windows on ARM 디바이스중에서 windows 게임을 가장 잘 돌릴 수 있는 디바이스다. 실제로 ARM64빌드가 아닌 x64빌드의 VOXEL HORIZON도 정상적으로 플레이 할 수 있었다.
반면 Surface Pro X에서는 ARM64빌드와 x64빌드 모두 정상 작동하지 않았다. 게임은 곧 크래시 했고 크래시 덤프를 분석해보니 D3D11 버퍼로부터 읽기 작업을 수행할때 실패하고 있었다. 정상적인 상황이라면 실패하지 않는다. 또한 간헐적으로 D3D리소스 할당에 실패했다.
이것은 퀄컴의 GPU드라이버 문제다. 작년 드라이버에서는 동일한 에러는 발생하지 않았으며 적어도 현재 버전의 드라이버보단 게임이 잘 작동했다.
이전 리뷰 글에서 SQ1의 GPU성능은 나쁘지 않음을 이미 확인한 바 있다. 당시에도 GPU드라이버의 안정성에 대해서 문제 삼았었고 2년이 넘은 지금까지도 해결되지 않았다. 오히려 더 나빠졌다.
결과적으로 Surface Pro X로 Windows on ARM타겟의 D3D 게임을 개발할 수 없다. 반면 해상도만 낮춘다면 m1 Mac에서 D3D11 그래픽 코드를 작성하고 테스트하는 것이 가능하다.
SSD I/O 성능 테스트
크리스탈디스크마크 어플리케이션으로 SSD의 성능을 테스트 하였다. 비교군은 ‘삼성 970EVO+ 1TB 2개를 RAID로 묶은 i7 8700K 데스크탑’, ‘2018년 출시된 Surface Book 2(512GB)’이다.


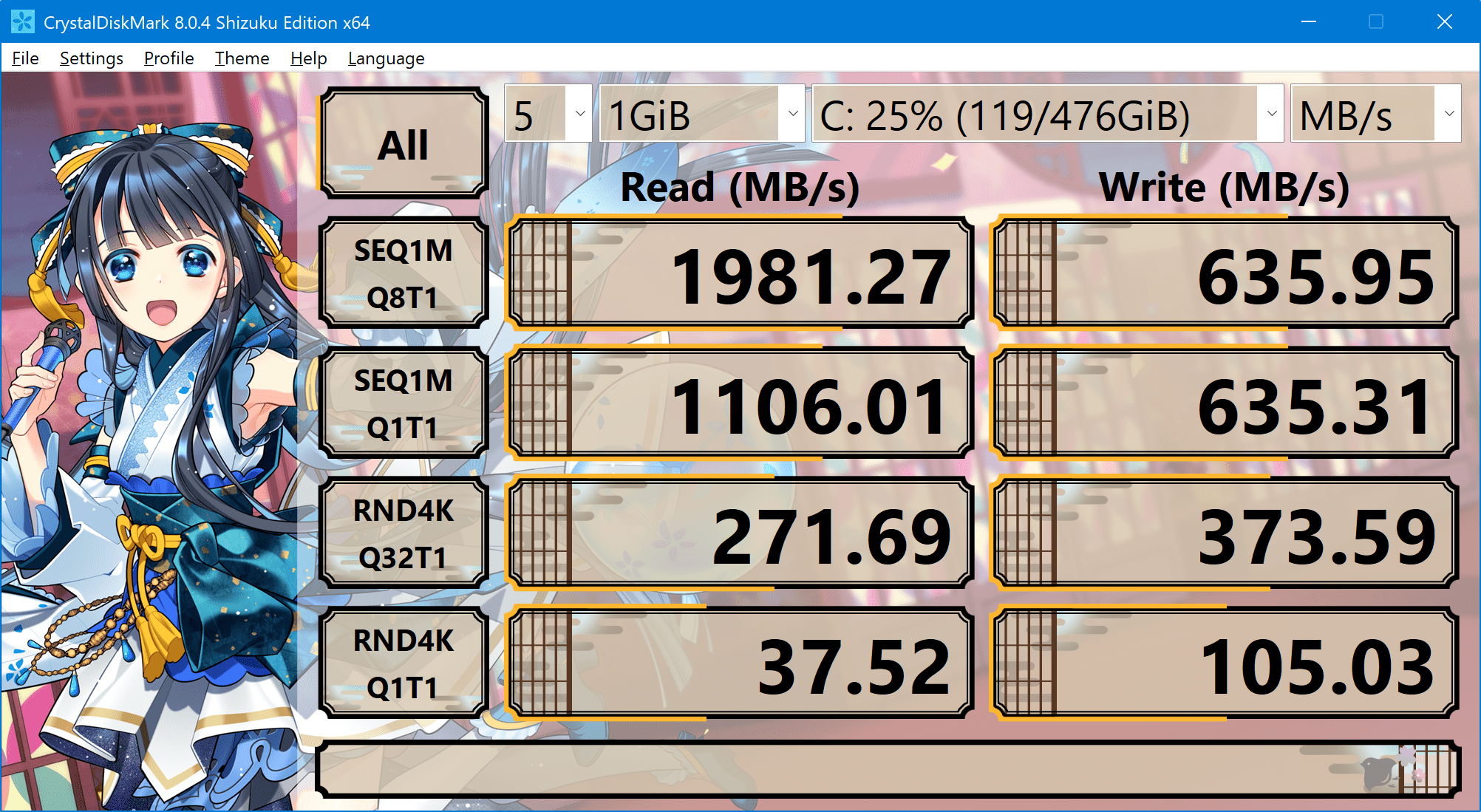
SSD I/O성능 테스트 결론
순차억세스에서는 압도적인 성능을 보여준다. 반면 랜덤억세스에서는 2018년 출시된 서피스북2보다도 나쁜 성능을 보여준다.
동영상 편집에서 사용하는 저압축 코덱에서 좋은 성능을 얻기 위해 iops를 포기하고 처리량에 집중했다는 지인의 분석이 있었다.
대용량 파일을 다룰때는 확실한 성능우위를 보일 수 있으므로, 그 점에선 대중들에게 좋은 인식을 심어줄 수 있었을 것이다. 실질적으로 어느 정도의 효용이 있는지는 약간 의문이지만.
결론
- m1은 전력대비 높은 성능을 보여준다
- 메모리와 I/O성능은 대단히 인상적이다.
- 그러나 모든 면에서 빠른것이 아니다. 흐름제어와 산술연산 능력에 있어서는 뛰어나지 않다. 오히려 기존 프로세서에 비해 떨어지는 성능으로 측정된다.
- GPU성능도 뛰어나지 않다. 애플이 의도한 어떤 특정한 작업에서는 m1의 GPU가 뛰어난 성능을 보일 수 있다. 하지만 통상적인 게임 그래픽에서 결코 좋은 성능을 보여주지 못한다.
- OpenCL/Vulkan등 표준적인 API사용이 불가하다. 따라서 정확한 비교가 불가능한데 이것은 애플이 의도적으로 타 플랫폼과의 비교를 피했다고 밖에 생각되지 않는다. 성능에 정말 자신이 있었다면 최소한 OpenCL과 Vulkan은 지원했어야 한다.
- Windows 게임을 플레이하기 위해 m1 mac을 구입하는 것은 나쁜 선택이다. m1 GPU의 실제 성능이 좋고 Parallels의 GPU드라이버 때문에 성능이 떨어지는 것처럼 보이는 것일수 있다. 그렇다 해도 m1 mac에서 windows 게임을 돌릴 방법은 Parallels 뿐이므로 windows 게임을 플레이하기 위해서 m1 mac을 구입하는 것은 나쁜 선택이다.
- 완벽한 것은 아니지만 Parallels의 안정성은 꽤 괜찮은 수준이다.
- 아이러니하게도 현재 Windows on ARM용 어플리케이션을 개발하기 위한 최적의 장비는 m1 mac이다. 레퍼런스 GPU라 할 수 있는 퀄컴 프로세서의 Adreno GPU는 Direct X 11조차 정상적으로 작동하지 못한다. 이것은 GPU드라이버의 문제이지만 2년 반 이상 해결되지 않고 있기 때문에 추후에도 해결되긴 어려울것으로 보인다.
- GPU드라이버 문제는 MS도 알고 있을 것이다. 그러나 그들은 별 관심이 없다.
- Windows on ARM타겟으로 어플리케이션을 개발하고 싶은 윈도우 개발자에게 m1 Mac mini를 추천한다. 이러한 용도라면 최고의 선택이다. 다만 이러한 용도만을 위해서라면 맥북 계열은 그만한 가격의 가치는 없다고 생각한다.
2022년 12월 11일에 추가
Windows Devkit 2023의 실물이 릴리즈되었고 지인의 도움을 얻어 직간접적으로 테스트를 해본 바, Windows on ARM환경은 Windows Devkit이 mac(m1/m2)+ Parallels 환경보다 명백하게 우월하다. GPU드라이버에 따라 왔다갔다하긴 하지만 D3D어플리케이션은 훨씬 빠르게 작동된다.
