Windows on ARM





I love Windows. Of course, I don’t have much attachment to Windows 3.1 and 95, but I really love Windows after the NT kernel. I also like Windows programming. Windows programming with Visual Studio is fun.
So I was very excited when I heard about NT kernel-based Windows running on a CPU other than x86. Using Visual Studio, I can develop Windows applications that run on ARM Device!
Of course, I was very disappointed with early Windows Phone 8 and Windows RT.
In the era of Windows 10 Mobile and Windows 10, the development environment has improved a lot. And while my complaints were reduced, they were still not satisfactory.
A large part of the complaint is that UWP APIs must be used to develop software for Windows on ARM devices. At this time, UWP APIs are definitely much better, but UWP API still have limited functionality compared to Win32 APIs. I spent a lot of time porting my game that I developed with win32 to UWP App . Why do I have to do this? I thought a thousand times that.
And a few years ago, Microsoft announced that it was developing a complete Window 10 OS that works on ARM devices. Since then, several companies, including Samsung, ASUS and HP, have released experimental devices for Windows 10 on ARM.
After suffering greatly from Surface RT, I had to take a very pessimistic view.
I know how many engineers have been struggling to develop Windows 10 on ARM. I respect them. But I think the future of WIndows 10 on ARM is pessimistic.
The x86 emulation is unstable and slow. There are no native apps for ARM.
But I am interested in Windows 10 on ARM as a software engineer. I was hit hard by Surface RT and hit hard by Windows Phone, but I’m still interested. From the first announcement until recently, I was still interested in Windows 10 on ARM.
Microsoft recently announced the Surface Pro X at a Surface event. The announcement was not a big surprise because HP or Samsung products are already on the market. However, I was very surprised that Microsoft released a product with Surface brand. If the Surface Pro X fails, the value of the Surface brand will also be hurt.
Looking at the Surface event, I was sure that consumers will regret it greatly if they buy this product. I think so now. I also wanted to buy Surface Pro 7 as a consumer and replace Surface Pro 2 at the bedside of my room. I was really going to.
Still, I was curious. What is the performance of the ARM Device, Surface Pro X, which was released under the name of Surface on MS, the performance of hardware? I was curious about the performance of ARM native code, not x86 emulation performance. Clearly, over the years, the performance of ARM-series processors has improved remarkably.
Microsoft has shown great confidence in the performance of the SQ1 processor that equpped in Surface Pro X. Of course I don’t believe it. The ‘Surface Book 1”s dGPU they were proud of also had poor performance.
I have been looked hard at the reviews of Surface Pro X posted on YouTube and on the review site since the actual launch of Surface Pro X took place. And I was very disappointed. I couldn’t get any information I want.
The article that criticizes the product,
They say “There are no apps that run slowly and quickly.”
The x86 emulation is of course slow. Of course, they consume a lot of batteries.
an article praising the product,
They say, “The thickness is thin, the shape is beauty and the weight is light.” Stupid? Electornic devices aren’t jewelry. I am more angry at these stupid reviews than at one-sidedly criticized ones.
As a programmer, I am curious about the real performance of the SQ1 processor, the stability of Windows 10 on ARM, and the environment for developing the ARM64 native app.
After a few days of rummaging through the reviews, I finally gave up. I can’t get the information I want from these stupid reviews.
So I paid my money to buy the Surface Pro X.
There’s no sponsorship! I paid for it!
I’ll write the code myself for the test!
Now I can see the things I’ve been wondering about. I’ll find out the information I want.


Direction and goal of the benchmark
I’m a programmer who writes software that goes into the game, so … the most important thing was how well the game can run on this device.
However, no game has been released as an ARM64 native app on win32 base. Even if it is, I can’t modify it off my own way, so it doesn’t mean anything anyway.
So I decided to port my game and the one I’m developing to ARM64.
Two weeks of testing and porting were done in parallel.
Code written in assembly language for x86 / x64 to support ARM64 is rewritten as standard C code. Performance sensitive math functions use SSE / AVX on x86 / x64. For a fair comparison, I wrote these functions for Neon (the SIMD instruction set for ARM64) additionaly.
Benchmarks are important, but since I got my Surface Pro X, of course, my game should run ‘well’ on Surface Pro X. My game should be run fine on Windows 10 on ARM. I could have completed the work faster if I simply benchmarked, but it took longer than expected because i continued to modify the code to make the game run well.
Finally, I decided that the game went well and then ran the benchmark.
In the case of arithmetic benchmark, I used the same code that is used in the my game.
I tested how well the features I use in my games and tools worked.
And as I said before, it’s not a performance comparison of ARM vs x86. Only one ARM processor was used for the test. Also all x86 CPUs are Intel’s products.
So exactly
Performance of native ARM64 by Qualcomm vs. Performace of Intel’s x86 Processors.
I also measured the performance of x86 emulation.It is 3 to 8 times slower than the ARM64 native code. Read only as a reference. The purpose of this benchmark is to understand the ARM64 native performance on SQ1 Processor.
Note that on the SQ1 processor, the SSE command set is also emulated. It can be emulated up to SSE4. AVX is not possible.
Arithmetic Operations Benchmark
This benchmark is single threaded. I do not measure the time spent. Rather, I measures the clock cycles consumed.
Some x86 CPUs have a high clock frequency. Therefore, when measuring the time spent, the performance of the x86 CPU is high.
This is a benchmark to measure the effectiveness of arithmetic operations.
Therefore, I measure how many clock cycles each operation consumes.
– big.LITTLE Architecture on SQ1 Processor
The SQ1 processor, like other ARM APs, uses the big.little architecture. It consists of four big cores of high performance and four little cores of low performance. The big core is called the Gold Core and the little core is called the Silver Core. The two types of cores differ not only in clock but also in instruction efficiency.
The little cores are numbered 0, 1, 2, 3, and the big cores are numbered 4, 5, 6, 7. All eight cores can be used simultaneously. I initially misunderstood the numbers of Golde core and Silver core and got wrong result. Since then, the gold and silver cores were explicitly specified and measured.
– SIMD(Single Instruction Multiple Data)
If the programmer does not explicitly write SIMD code, but writes standard C code, the compiler does not automatically gererate SIMD code. The compiler only uses single instructions and registers in the SIMD instruction set . This is faster than using a traditional FPU code.
If it is marked SIMD in this test, it is an explicitly written SIMD code.
No SIMD indicates that the code is written in standard C code. However, the compiler uses SIMD registers and instructions instead of FPU, which is faster than using only FPU. As a result, there can be little or no performance difference with the SIMD code.
I used SSE for the SIMD code for x86 / x64 and Neon instruction extensions for the code for ARM64.
For x86 CPUs, depending on the situation, it may be able to use AVX for further performance. Meanwhile, I wrote Neon code for the first time. My code may not be efficient enough. Therefore, it is impossible to determine exactly which is the highest performance of the SIMD.
This test is intended to determine the level of performance of modern ARM64 processors, not to rank them.
Basic arithmetic operation benchmark
This is the benchmark of the arithmetic operation of the float4 variable. In games, I usually use 3D vectors (float3) to save memory. The float3 type cannot be read from memory at one time and cannot be written to at once. Therefore, there is an additional cost in reading and writing to memory. This test uses a four-dimensional (float4) vector because its purpose is to test how fast arithmetic is.
Addition and subtraction are basically the same operations, so I did not test subtraction separately.

Instead of repeating the same kind of operation, the Add or Sub Or Mul or Div test branches into four operations based on the index of the vector array passed. This is to deliberately induce cache misses and confuse branch prediction. The Intel x86 CPU is clearly superior in this test.
Vector and Matrix Arithmetic Benchmarks
Here I benchmark the functions that are used a lot in game programming. I used the math functions in my game project.
Since the TransformVector_xxxx () functions take a float3 stream as an array, the function call cost can be ignored. However, Matrix multiplication, Normalize (), CrossProduct (), and DotProduct () perform one operation at a time, so the clock cycles consumed includes the cost of calling the function.
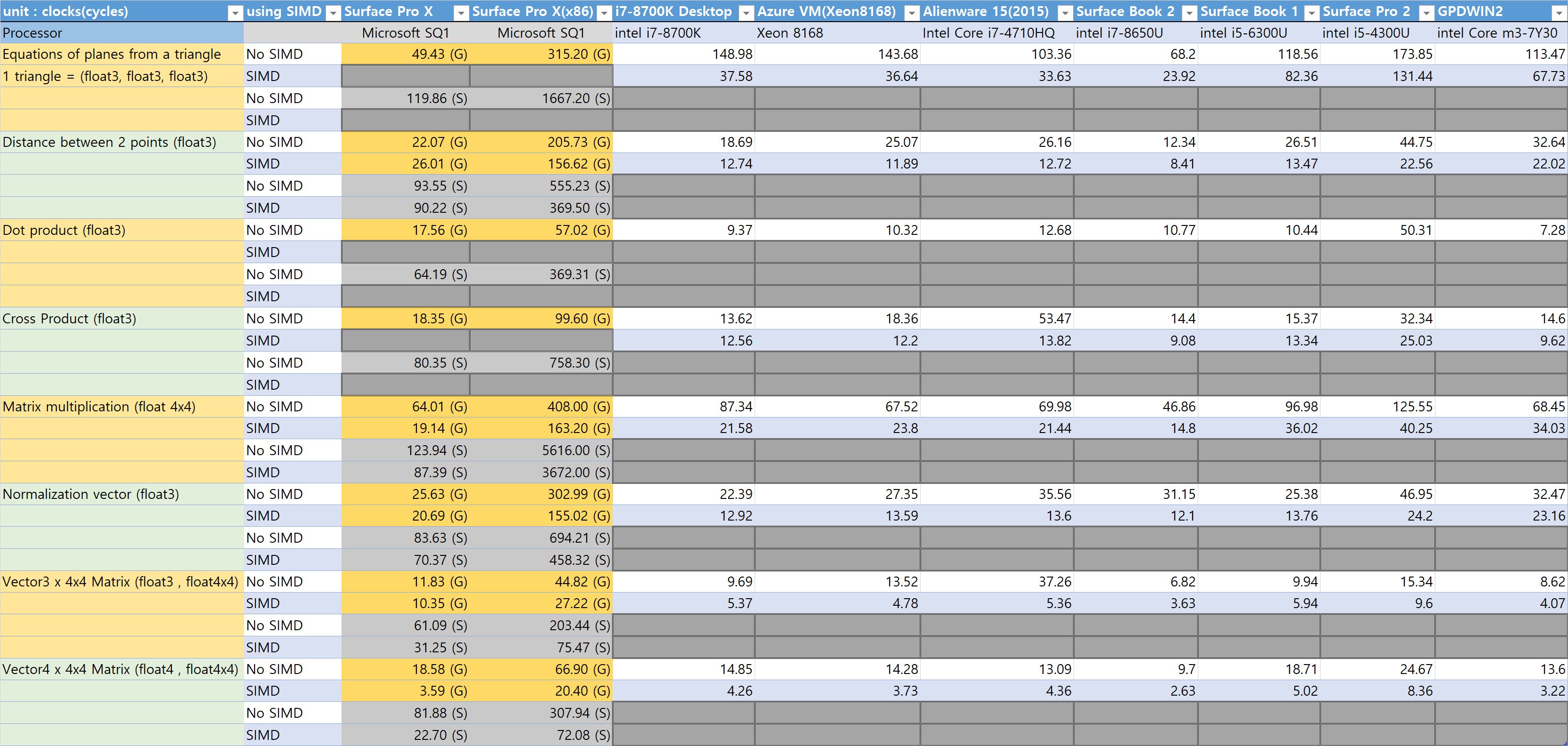
Conclusion of Arithmetic Operations Benchmarks
As a result, Intel x86 is faster than SQ processors. Contrary to initial expectations, however, the performance of the SQ1 processor is not much lower than Intel x86. In some benchmarks, ARM64 is faster. In terms of SIMD performance, the performance difference is smaller.
Overall, the x86 family performance is higher than SQ1 processor.
But I don’t think this performance difference is enough to feel in the game.
SQ1 processor has enough performance to run the game.
memcpy() benchmark
Copy 1 GiB of memory using memcpy () in VC ++.
Here I use multithreading.
Dividing 1 GiB of memory by the number of active threads, each part of memory is copied by all threads at tsimultaneously.
No synchronization object is used because no synchronization is required between threads.

Conclusion of memcpy benchmark
The measured bandwidth does not reach the official bandwidth of the SQ1 processor and the official bandwidth of the Intel CPUs.
However, memcpy () comparison is enough as a performance indicator because memcpy () is a very popular memory copy function and in most cases guarantees high performance.
The memory transfer capability of the SQ1 processor is very good. Performance is higher than other x86 cpu using two-channel buses, except for xeon cpu that uses a four-channel bus (clearly bandwidth with official specifications).
The Multithreading Responsiveness benchmarks
This test measures the cost of context switching and the cost of synchronization between multiple threads.
When I first ported my game and tool code to ARM64, the performance was not satisfactory. The tools that actively use multithreading were particularly bad, so I speculated that there might be a problem with multithread responsiveness in ARM64.
Basically, multiple threads competitively increment the 4bytes variable until it reaches target value.
Each test has a different method for synchronization between multple threads.
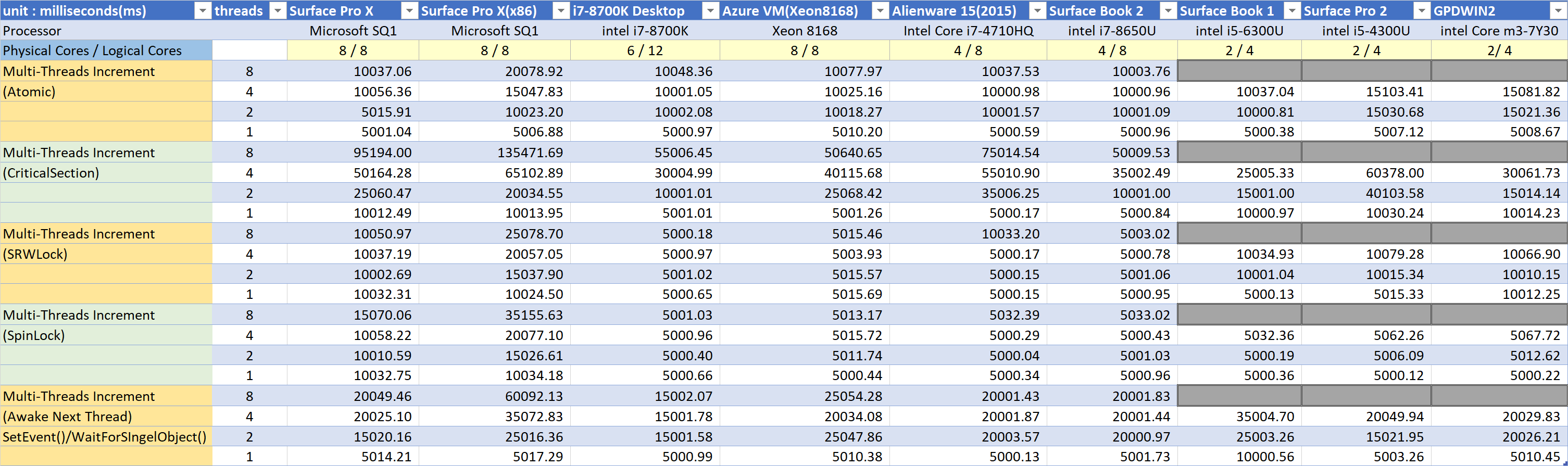
The Atomic increment Test is a test that increments a 4-byte variable without using a lock object. If it is x86, it is expressed as a single line of ‘lock inc dword ptr [mem]’ in assembly language.
I was wondering if there was a performance penalty on the ARM CPU.
At 1, 4 and 8 threads, the SQ1 processor and Intel x86 perform almost identically. Rather, the SQ1 processor is measured as having better performance in 2 threads.
The Critical Section Test synchronizes threads that increase variable values using critical sections. If a thread first enters a block of code wrapped in a critical section, the thread trying to enter is not scheduled until the first thread leave the critical section. That is, the late thread is waiting. There is a delay before the thread is rescheduled. The larger the number of threads, the worse the performance. It’s a very bad situation.
In this situation, I wanted to know how much the SQ1 processor and the Intel x86 CPU would be degraded.
In this situation, the performance of the SQ1 processor seems to be greatly reduced. If the application uses a large number of critical sections or similar types of synchronization, there will be a significant performance penalty on the SQ1 processor than Intel x86 CPUs.
SRWLock is a popular lightweight synchronization object. Internally implemented as a spin lock. It is written in very efficient code. If it use only spin lock, if the thread that entered first does not escape for a long time, the thread that tries to enter will be busy, which can reduce the overall system performance. SRWLock is prepared for this. If the thread that tries to enter fails to enter more than a certain number of times, it will be in a waiting state, which can avoid performance degradation.
In this test, Intel x86 clearly high performance than a SQ1 processor.
The Spin Lock Test synchronizes the threads using a spin lock that I create. Similar to SRWLock, but with a difference. Even if the first thread does not leave from code block for a long time, the next thread does not wait. The thread spins and keeps trying to enter.
Obviously it is used to synchronize code blocks that will end in a few hundred clock cycles. The ‘lock cmpxchg’ insruction is used, and the spin lock implementation itself is almost identical to SRWLock.
Even in this test, Intel x86 clearly high performance than a SQ1 processor.
Poor performance of SQ1 ARM64 when using spin lock
‘CAS implementation in ARM does not end with one instruction. It must try to loop repeatedly. So the code is longer, so it’s slower. ‘
For x86, the lock cmpxchg instruction ends with one line, but internally it will loop. Nevertheless, the x86 approach will be more efficient.’
I thought so.
[_InterlockedCompareExchange() – x64]

[_InterlockedCompareExchange() – ARM64]

In the ‘atomic increment test’, however, there was little difference in performance between x86 and ARM. Rather, ARM64 was faster on two threads.
Check the _InterlockedIncrement () assembly code used here.
[_InterlockedIncrement() – x64]

[_InterlockedIncrement() – ARM64]

For ARM64, the code that performs the exclusive writing operation is the same as the exclusive writing code for _InterlockedCompareExchange ().
The code is much longer than x86. Nevertheless, performance is measured at the same or higher level.
If arm64 is simply slow because of long code, arm64 should have been a lot slower in ‘atomic increment test’.
I’m not a CPU expert and I don’t know much about ARM. Eventually I concluded that the reason was unknown.
To be sure, intel x86 is much faster when using spin lock.
The (Awake Next Thread) Test tests how much delay there is when a waiting thread wakes up.
Each thread is operated by biting each other’s tails. This is a kind of round robin.
For example, if it test with three threads,
- Thread 0 increments the value of the variable and then calls SetEvent (event [1]) to wake up thread 1. Then waits by calling WaitForSingleObject (event[0]);.
- 1Thread 1 increments the value of the variable and then calls SetEvent (event [2]) to wake up thread 2. Then waits by calling WaitForSingleObject (event[1]) ;.
- Thread 2 increments the value of the variable and then calls SetEvent (event [0]) to wake up thread 0. Then waits by calling WaitForSingleObject (event[2]) ;.
- Repeat until the variable reaches the target value.
The results show no significant performance difference between the SQ1 processor and the Intel x86 processor.
When multiple threads are not in contention, multithreading responsiveness is no difference between the Intel x86 and SQ1 processors.
Conclusion of multithreading responsiveness benchmark
If many threads are trying to acquire lock object competitively (including spin locks), the SQ1 processor seems to be slower than Intel x86.
If no synchronization is required, the latency seems to be about the same for the threads being scheduled.
If it need to synchronize between threads to get the most out of all cores, it will get better performance on x86
voxel data processing benchmark
Therer is a voxel based game project I’m developing.
I tested the tools and game features.
It is a test that makes the best use of CPU performance with multithreading, and GPU performance is also important.
I ran three benchmarks.
Loading map of voxels
Load a map with 15 million voxels of 50cm x 50cm at once. In actual games, only some data is sent from servers based on current location. It can be loaded at once in offline mode.
The voxel data is compressed. After loading the file, it decompress to create the vertex,index data and create triangular data for collision processing. These operations are performed at the same time by multiple threads as many cores. When the generation of geometric data is complete, the light map is baked. If the light map baking is not yet completed, it will be rendered as white. CUDA can be used for the light map baking if nvidia GPU is equipped. If it use CUDA, the performance is overwhelmingly good.
Baking Light-map
The voxel world uses a light map. The light map is automatically baked immediately after loading the world, or when part of the terrain is transformed. Users can also bake the world-wide light map at one time. As many threads as the number of logical cores calculate and update the light map.
updating frames of the game will be stopped until the light map baking is finished and updated to the textures. I measure how long it takes to bake the light map. (CUDA can also be used here. CUDA si very fast. Unfortunately, CUDA is not available on Surface Pro X.)
Voxelization
voxelization the feature is to obtain the terrain data needed for the game from the already created triangular modelling data.
Convert modeling data from triangular bases into voxel data. The voxel data required for this type of game should be solid voxel data. Thus, simple cross-determination of triangles does not provide the desired voxel data. There are many ways. I use the way that are quite ignorant and dependable.
It takes full advantage of CPU and GPU power to achieve its goal.
I use DirectX 12 because DirectX 11 allows only partial multi-threaded access. Personally, I have a lot to say about the performance of DirectX 12, but in this case, DirectX 12 is a little better performing. I create a Commane Queue (number of logical cores) to fill the GPU’s H/W queue.
You can see that the CPU and GPU ratios are achieving 100% throughout the test
Surface Pro X vs intel x86 + dGPU devices

Loading map of voxels benchmark results
That’s half the performance of SurfaceBook 2. Considering the rating of the device, I think it is not bad. At first, I expected performance to be worse than Surface Pro 2. It is better than GPDWIN2 and Surface Pro 2.
When I first developed this game, I thought of Surface Pro 2 as the minimum device, so this is satisfactory.
Baking Light-map benchmark results
Surprisingly it’s faster than Surface Book 1. Four of the eight cores are dumb, but they still show the power of eight cores. That’s 70% of Surface Book 2. Much higher than expected.
Voxelization benchmark results
The result is faster than Surface Pro 2 but slower than GPDWIN 2. When I ran my old game on DX12, there was a serious performance penalty. I suspect that there is a performance problem with Qualcomm’s GPU driver for DX12.
Conclusion of voxel data processing benchmark
Since the four cores are “little(silver)” cores, it doesn’t show the multi-threaded performance I might expect.
Collaboration with CPU + GPU is particularly bad. I think there is a problem with the performance of the GPU driver. The GPU driver doesn’t seem to be able to submit commands to the GPU H / W queue smartly.
Game FPS benchmark
I measured framerate with a game I developed a long time ago.
The game was developed a long time ago, but the code is up to date because the code has been modified continuously. The game also supports DirectX 12.
Performance of Qualcomm’s DirectX GPU driver drops dramatically when lots of draw() called. Bottlenecks occur in submitting commands. During this time, the GPU waits.
This game does not have many draw calls. This makes it easy to get close to 100% of the GPU.
It can compare the performance when the GPU usage close to 100% to measure pure GPU Performance.
I load a village map with a lot of objects and set the camera view in the same location and in the same direction. The frame rate was measured for each resolution.
All devices were tested at 1920×1080 resolution in common. In addition, the maximum resolution of each device was tested.

Poor frame rates compared to devices with mid-range or higher dGPUs, but with significant performance for an embedded GPU. It’s almost comparable to the dGPU on Surface Book 1. It’s probably going to show similar or higher performance than most x86 Surface Pro products. I’d like to compare it with Intel’s built-in GPU in Surface Pro 7, but I didn’t test it because I don’t have Surface Pro 7.
Conclusion of Game FPS benchmark
The hardware performance of the GPU is enough. It’s hard to run AAA games, but I think if the game runs on Intel’s built-in GPU, it can run on this device. At least in terms of hardware performance.
However Qualcomm’s DirectX GPU driver has a problem. In addition to performance issues, there are some bugs.
If the driver problem is solved, I want to release the game with ARM64 target.
Some problems.Things that need improvement
Excessive memory consumption
When tested with my game project, running on Surface Pro X consumed 50% more memory than on an x86 machine.
An app that used to consume 2GB of memory consumes 3GB with the ARM64 build. Most of the memory is explicitly managed using my own memory pool. Therefore, it is suspected that this is additionally consumed by DirectX Runtime or GPU driver.
GPU driver issue for DirectX.
- More Draw () calls can seriously degraded performance. More draw () calls are even slower than Surface Pro 2. I think there is a problem with the scheduling of the GPU user-mode driver.
- Driver crashes when accessing Direct3D 11 Deivice as multithreaded. ID3D11DeviceContext is not thread safe. But ID3D11Device is thread safe. This allows multiple threads to create and remove D3D resources at the same time. But on the current Surface Pro X, it crashes in the driver (maybe user-mode driver). I could see the following error message.D3D11: Removing Device.
D3D11 WARNING: ID3D11Device::RemoveDevice: Device removal has been triggered for the following reason (DXGI_ERROR_DRIVER_INTERNAL_ERROR: There is strong evidence that the driver has performed an undefined operation; but it may be because the application performed an illegal or undefined operation to begin with.). [ EXECUTION WARNING #379: DEVICE_REMOVAL_PROCESS_POSSIBLY_AT_FAULT]
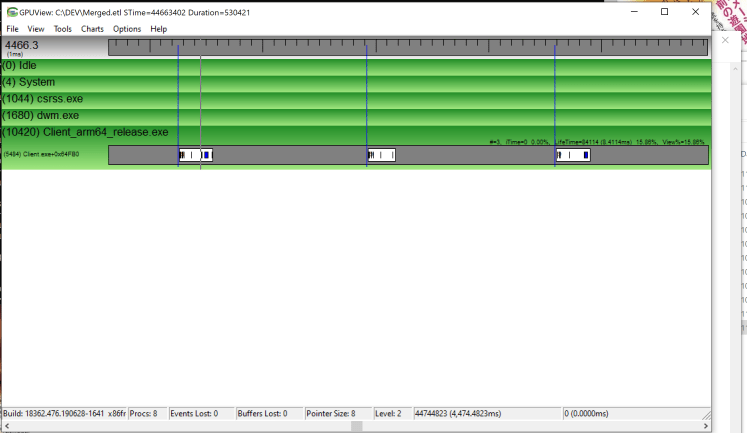
Exception thrown at 0x00007FFF8F6A4024 (qcdx11arm64um8180.dll) in MegayuchiLevelEditor_arm64_debug.exe: 0xC0000005: Access violation reading location 0x0000000000000028. - performace counter is not supported. I tried to analyze the graphics rendering status with GPUView on Surface Pro X. I captured the .etl file but there is no GPU information at all, as shown in the screenshot.
The Windows Game bar also works, but with a GPU usage is 0%. This is invalid informatiion. The frame rate was not shown at all. I think it’s a GPU driver’s problem.
GTX1660TI

Surface Pro X
Conclusion
- In general CPU operations – arithmetic, reading from and writing to memory, the ARM64 performance of the SQ1 processor is satisfactory.
- When using spin lock, performance is significantly lower than intel x86. Also when it in a bad situation with multithreading, such as using Critical Sections, performance is significantly lower than x86.
- It’s still slower than intel x86. In addition to the clock frequency, instruction efficiency is still lower than Intel x86.
- But that’s enough to use as a laptop (assuming it running apps for ARM64). CPU performance is not severely degraded compared to Intel x86. Sometimes it’s better than x86. GPU performance in particular is impressive.
- At the moment, there are problems with Qualcomm’s GPU drivers. Both performance and stability are a problem with DirectX.
- If popular productivity applications are released for ARM64, I think it can provide a working environment that is not lacking compared to x86 devices.
- If the GPU driver improves, I think the game that runs on the x86 Surface Pro can run smoothly.
- x86 emulation performance is significantly lower than that of native ARM64. If the Windows on ARM ecosystem has to rely on x86 emulation, there is no future.
Video of my game ported to ARM64.
[Project D Online on Surface Pro X]
[Voxel Horizon on Surface Pro X]

Dear megayuchi.
Very good article and deep, well substantiated review.
Please note that, while VC++ still does not offer intrinsic operations for it, ARMv8.1 processors do also support Intel-like SWP and CAS instructions. For the moment, you do have to use assembly code and the ARMASM64 assembler to use those instructions.
They are, as you’d expect, faster than the loop around load-reserve/store-conditional classic ARM solution for heavy contended locks (the performance is almost the same for non-contended locks).
좋아요Liked by 1명
I see. Thank you for good information.
좋아요좋아요
The reason why AcquireSpinlockWithYield is so slow is, that the implementation is awful. Microsoft is using memory barriers all over the place, while this is not necessary if you are using load/stores with acquire and release semantics, where the barriers are implicit. When properly implemented this should always be faster than swp on x86.
You can even remove the barrier at the end of InterlockedIncrement for even faster performance.
Another word to YIELD. This is a nop on ARMv8…instead the implementation should use WFE, which puts the core into a low power state.
좋아요좋아요
Well, load-aqc / store-rel instructions are not v8.0 compatible, they are also not read-modify-write, do they, alone, can’t solve the problem.
Also, the barriers that are being generated are the correct barriers if you don’t specify the direction of the barrier you want. In absence of information, the compiler has to generate the code that will enable correct execution.
To make things better, you can (and should), Interlocked*Acquire and Interlocked*Release intrinsic operations, which will cut the barriers in 1/2 and still be 8.0 compatible.
That improvement to the implementation will make things better.
If you want to use oad-aqc / store-rel instructions for the cases where you don’t need a read-modify-write, then you can also use them but you’ll need to use ARMMASM64, just like if you want to use CAS and SWP. Note that you will be making your code require v8,1 from then on.
But, instead of all this, why not use the OS provided SRW locks, Wait on Address and Conditional Variables?
좋아요좋아요
@Pedro:
I was just commenting what is wrong with the current MS provided implementation. In fact you can remove all the barriers in the above listed implementation and it would be still perfectly fine. Not sure what drove MS using memory barriers … they should have read the manual.
In general on any modern CPU using LL/SC mechanism is the way to go even for a single atomic add. Locked swap operations have been deprecated in ARMv7 already. In fact even the AMBA spec deprecates locked transactions – they are gone in AXI4.
If properly implemented LL/SC in particular with acquire/release semantic will easily outperform any x86 implementation based on locked exchange and the likes.
Yes, currently the option is to implement spinlocks and atomics as asm-function in a separate file, which has the disadvantage of not being inlined, wait for MS to add the needed intrinsics or better yet wait for MS to provide an effcient implementation without superfluous barriers.
좋아요좋아요
Quick update. I figured that “AcquireSpinlockWithYield” is not from MS but the implementation of megayuchi, where he is using _InterlockedCompareExchange() to implement the spinlock, right?
That explains something.
Ok then assuming we have the instrincs a spinlock conceptionally should look like follows:
mov wx, #1
sevl
_retry0:
wfe
_retry1;
ldaxr wy,[mem]
cbnz wy, _retry0
stlxr wy, wx, [mem]
cbnz wy, _retry1
Works for any ARMv8-A variant. If we have v8.1A we can optionally use CASAL instruction.
Sorry for the confusion.
좋아요좋아요