요 근래 계속 붙잡고 있던 SW Occlusion Culling을 거의 마무리 지었다.
물론 오래전에 HW Hierarchical Occlusion Culling을 구현해서 지금까지도 잘 사용하고 있다.
SW Occlusion Culling을 만든 이유는 HW Occlusion Culling을 대체하기 위함이 아니다.
전혀 아니다. 이것은 완전히 용도가 다르다.
현재 복셀 월드는 KD-Tree로 공간이 분할되어있다. 그리고 보여지는 오브젝트를 찾아내기 위해 트리를 탐색한다. 이 탐색 과정에서 node 단위로 Occlusion Culling을 걸어서 일찌감치 제거해버리면 그 하위 node를 탐색할 필요도 없고 그 안에 포함된 오브젝트들에 대한 view frustum검사도 할 필요가 없다. HW Occlusion Culling에 들어갈 Occluder와 Occludee 오브젝트 개수도 줄어든다.
그런데 CPU로 시스템 메모리에 있는 트리를 탐색하면서 GPU를 이용해서 Occlusion Culling을 수행할수는 없다. GPU에 일을 시키려면 그래픽API를 사용해야하는데 셋업과정이 너무 길다. 그리고 결과를 가져오는데도 오래 걸린다. GPU에 일을 시키려면 한번에 몰아서 해야 효율적인데 여기서 지금은 node하나 탐색할때마다 Occlusion Culling을 하려고 한다. 결국 트리 탐색중에 GPU에 Occlusion Culling을 맡기는건 불가능하다.
그래서 SW Occlusion Culling이 필요하다. 처리량은 떨어지지만 응답성은 좋다.
SW Occlusion Culling을 위해서 SW Rasterizer로 어느정도 구현했고 잘 작동한다(이 내용은 따로 포스팅할 예정이다).
우선 culling결과만 놓고 보면 좋다. 아주 좋다. 이 스샷의 상황은 3인칭 시점의 카메라가 벽 뒤에서 광장쪽을 바라보고 있다.

HW Occlusion Culling on / SW Occlusion Culling on
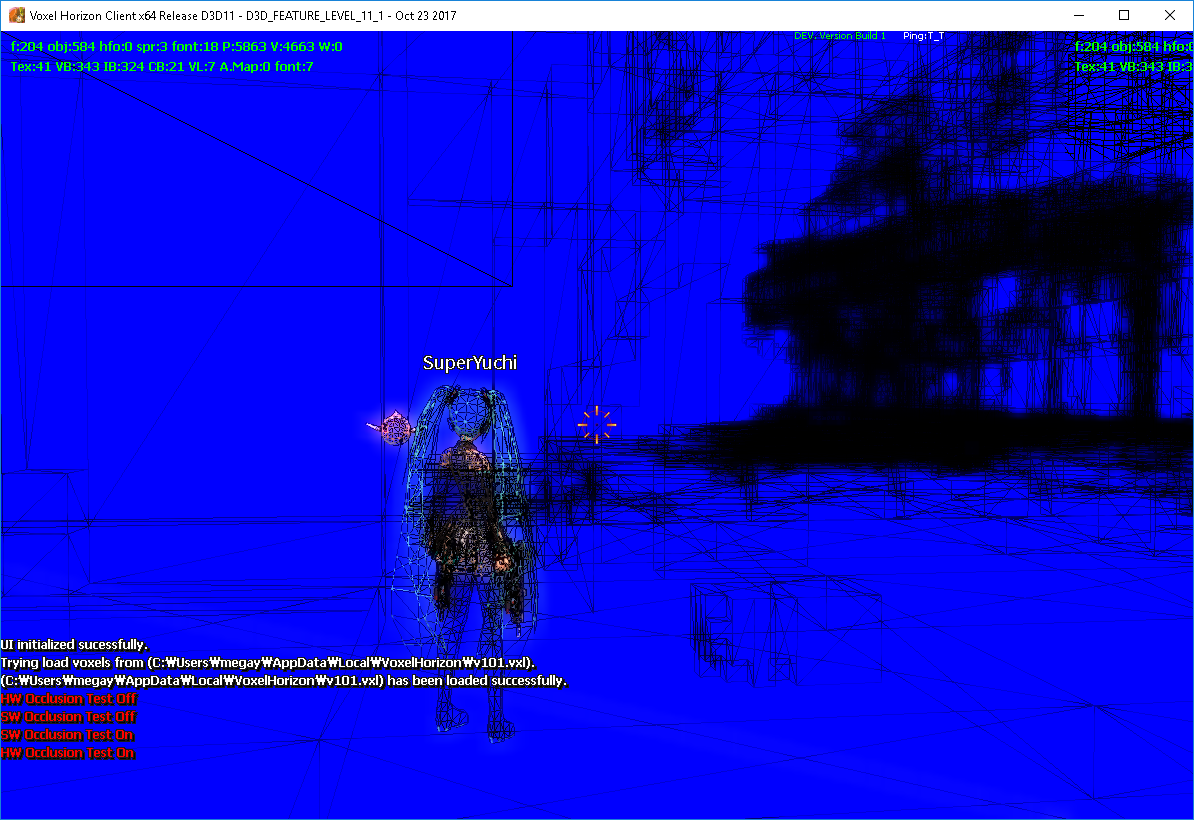
HW Occlusion Culling off / SW Occlusion Culling off

실제로는 이만큼 벽 뒤에 오브젝트들이 이만큼 있다.
Only SW Occlusion Culling On

마지막 node를 탐색할때까지 SW Occlusion Culling을 적용하면 Hierarchcal HW Occlusion Culling보다 더 많은 오브젝트들을 제거해준다.
하지만 역시 속도가 문제다. 매 프레임마다 마지막 노드를 탐색할때까지 SW Occlusino Culling을 걸면 꽤 느리다. 전체적으론 더 느려진다. 특히나 뻥 뚫린 곳에서는 정말로 아니함만 못하다. 한 프레임당 Occluder로 5만개 이상의 삼각형을 Rasterize해야한다. 이건 무리다.
그래서 다음과 같이 최적화 작업을 진행했다.
1. SIMD최적화
SSE와 AVX를 사용해서 같은 클럭에 최대한 많은 작업을 동시에 처리하도록 했다. 단 아주 큰 이득은 보지 못했다. 20% – 30%정도 성능 향상이 있었던것 같다. 트랜스폼된 삼각형이 화면상에서 충분히 커야 SSE로 4픽셀, AVX로 8픽셀씩 그리는게 의미가 있는데 현재 50cm짜리 복셀들로 맵을 구성하고 있으므로 얘네들을 Occluder로 그리면 화면상에 그려지는 삼각형 사이즈가 너무 작다. 그나마 node를 test하는 경우는 화면상에서 차지하는 면적이 크므로 SIMD를 사용하는 쪽이 확실히 빠르다.
2. Multi Thread
Rasterize시에 멀티스레드를 사용할 경우 depth 버퍼 억세스를 위한 동기화에서 상당한 시간을 소모한다.
사실 이보다 큰 문제는 따로 있다.
node가 leaf일 경우 오브젝트들 Rasterize -> 다음 node 테스트 ->
node가 leaf일 경우 오브텍즈 Rasterize -> 다음 node 테스트 -> ….
이렇게 반복하면서 매번 워커 스레드가 작업을 완료하기를 기다려야 한다. 이제 가장 치명적이다. 따라서 이런 방식의 스레드는 사용하지 않는다.
삼각형을 Rasterize하거나 Test하려면 두가지 공정으로 나눌 수 있다.
- 세 점을 트랜스폼해서 NDC좌표계로 바꾸고 클리핑 하는 과정.
- 세 점으로부터 빗변의 기울기를 구하고 스캔라인 따라가며 버퍼에 그리거나 테스트하는 과정.
2번은 멀티스레드로 처리하려면 버퍼에 lock을 걸어야한다. 하지만 1번은 depth 버퍼를 억세스하지 않으므로 완전히 완전히 병렬로 처리할 수 있다.
그래서
- node를 방문했을때 이 node가 leaf이고 오브젝트들을 가지고 있다면 그 즉시 오브젝트들의 삼각형 리스트를 비동기로 transform(1번작업)시킨다. 이때부터 백그라운드에서 다수의 워커스레드들이 입력받은 삼각형 데이터를 클리핑된 NDC좌표 삼각형들로 바꿔나간다. 완료된 오브젝트에 대해서는 intelock변수 하나로 표시만 해둔다.
- 메인 스레드는 워커 스레드들이 완료하기를 기다리지 않고 Rasterize작업을 시작한다. 앞서 요청한 트랜스폼 작업의 interlock변수가 ‘완료됨’으로 표시된 경우 트랜스폼된 삼각형 데이터를 가지고 바로 버퍼에 그린다. interlock변수가 완료되지 않음으로 표시된 경우 비동기로 요청한 작업은 무시하고 메인 스레드가 직접 트랜스폼 -> 그리기 작업을 진행한다.
이것은 일종의 prefetch cache다. 메인스레드가 비동기로 걸어놓은 트랜스폼 작업이 때마침 완료되어서 트랜스폼을 생략할 수 있으면 hit, 완료되지 않아서 메인스레드가 트랜스폼부터 다시 하는 경우가 miss다. 현재까지 테스트한 바로는 Nehalem 아키텍처의 구형 머신에선 80%이상, 샌디브릿지 이상 i7 4코어에선 95%이상 히트한다.
3. 시간제한
이렇게까지 해도 만족스럽진 않았다. SW Occlusion Culling효율이 안나오는건 사실 큰 문제는 아니다. 그보다는 SW Occlusion Culling자체로 시간을 너무 잡아먹어서 전체적인 프레임 레이트를 왕창 떨어뜨리는게 훨씬 큰 문제다.
그래서 최악의 상황을 막기 위해 시간제한을 걸었다. 트리 탐색중 Rasterize와 Test작업 각각에 일정 시간을 소모하면 작업을 중단한다. 즉 SW Occlusion Culling을 끄는 것이다. 일반적으로 Rasterize에 총시간이 더 많이 들어가므로 Rasterize와 Test 각각 다르게 시간제한을 둔다. Rasterize를 중단해도 이미 depth버퍼를 약간이라도 구성해놓은 상태이므로 Test를 더 진행할 수 있게 하기 위함이다.
여기까지 하고 마무리 지으려 했으나.
당연히 Occluder로 사용하는 삼각형들을 충분히 그려놔야 이후 node를 구성하는 삼각형들을 Test하는 작업도 의미가 있다.
그런데 많은 경우 시간제한에 걸려서 Occluder삼각형들을 충분히 Rasterize 하지 못하는 상태가 된다.
현재 Rasterize에 2ms, Test에 1ms 시간제한을 두고 있는데 너무 짧은 시간이라 만족스러운 결과가 나오지 않는다.
이 경우 depth버퍼에 아예 삼각형을 그리지 못한 공간이 많은데 node를 테스트할때는 depth버퍼의 빈 영역에도 test를 시도하고 있다.
특히 초기에 탐색하는 node일수록 화면상에서 차지하는 사이즈가 큰데 이 큰 삼각형들을 텅 빈 depth 버퍼에 대고 깊이 테스트하는 것은 굉장한 낭비다.
그래서 다음과 같이 해결했다.
Tile Buffer
16×16짜리 타일버퍼를 만들었다. 화면을 16×16으로 나눴다.
depth 버퍼 클리어할때 타일버퍼도 0으로 클리어한다.
Occluder 삼각형을 rasterize할때 트랜스폼후 NDC좌표계 나오면 이 삼각형이 차지하는 타일버퍼 영역에 1을 써넣는다.
이후 node를 테스트할때 node의 삼각형이 차지하는 타일버퍼의 값을 읽어서 0이면 depth test까지 가지 않고 그대로 true를 리턴한다. depth 버퍼가 비어있으니 이 노드를 가리는 삼각형은 당연히 전혀 존재하지 않고, 이 node는 무조건 그려진다.
불필요한 test를 건너뛰는만큼 남는 시간에 정말 가려질 가능성이 있는 node를 몇 개라도 더 테스트할 수 있다.
시간제한을 걸지 않았을때 depth버퍼와 타일버퍼. 검정색 영역이 depth값이 존재하지 않는 영역이다.

시간제한을 걸었을때의 depth버퍼와 타일버퍼. 시간제한에 걸려서 충분히 Occluder를 그리지 못했고 그래서 빈 공간이 많다. 타일버퍼에서 이에 해당하는 영역이 0으로 채워져 있고 검정색으로 표시되고 있다. 이 영역에 대해서 node의 삼각형들을 트랜스폼했을때 이 영역에 들어간다면 test를 수행하지 않고 화면에 렌더링될 node로 간주한다.

이렇게 고치고 효과가 꽤 있다.
rasterize 2ms, test 1ms만으로도 내가 원하는 상황-벽에 가려진 상황일 경우 상당히 많은 가려진 node들을 제거했다.
타일버퍼를 적용한 뒤의 스샷이다.
HW Occlusion Culling on / SW Occlusion Culling on

Only SW Occlusion Culling

HW Occlusion Culling off / SW Occlusion Culling off

SW Occlusion Culling은 진짜 이걸로 끝.
p.s :
이 내용으로 ppt를 만들고 있었는데 멀티스레드 최적화쪽이 결론이 안난 상태여서 무기한 보류하고 있었다. 오늘(2018/08/01) ppt자료를 마무리 해서 업로드했다.
